Angjoo Kanazawa
 |
I am an Assistant Professor in the Department of Electrical Engineering and Computer Sciences at the University of California, Berkeley. I lead the Kanazawa AI Research (KAIR) lab under BAIR. Alongside my academic work, I have served as Chief Technical Advisor for Luma AI and on the advisory board of Wonder Dynamics. CV | Google Scholar | twitter | bluesky Email: kanazawa (at) eecs.berkeley.edu |
Dear prospective students: Click here for information.
News
- April 2025: Talk at the MIT Robotics Seminar:
- October 2024: Gave talks at ECCV 2024 workshops:
Details and slides
- 9/29 Sunday 11:00am 3D Vision and Modelling Challenges in eCommerce: I will talk about how to scale NeRFs across multiple GPUs (ECCV 2024), and the latest updates on our opensource tools: nerfstudio, gsplat, and viser: Slides
- 9/30 Monday 9:45am VENUE: Video Content Understanding and Generation: about our latest works in 4D reconstruction like Shape of Motion, challenges thereof, and more.
- 9/30 Monday 11:10am Wild3D: 3D Modeling, Reconstruction, and Generation in the Wild: about incorporating semantics — grouping — in 3D, and how to use part knowledge for 4D reconstruction of objects with movable parts for robotics! We just released this work, to be presented at CoRL 2024 (oral).: Slides
- 9/30 Monday 2:35pm AI for 3D Content Creation: about our new NeurIPS 2024 paper that makes sense of SDS!: Slides
- 9/30 Monday 4:50pm Foundation Models for 3D Humans: last but not least, about hard problems that need to be solved for 3D human foundation models and our latest work EgoAllo: Slides .
- June 2024: Received the PAMI Young Researcher Award, thank you!
- Oct 2023: Talk on
Creative Horizons with 3D Capture
at Stanford HAI Fall Conference. Link - March 2023: GTC talk on nerf.studio: Link
- February 2023: Named a 2023 Sloan Research Fellow, thank you!
- October 2022: We ran a tutorial on NeRFs at ECCV 2022, all videos here.
Research
My research lies at the intersection of computer vision, computer graphics, and machine learning. We live in a 3D world that is dynamic, full of life with people and animals interacting with each other and the environment. How can we build a system that can capture, perceive, and understand this complex 4D world like humans can from everyday photographs and video? More generally, how can we develop a computational system that can continually learn a model of the world from visual observations? The goal of my lab is to answer these questions.Kanazawa AI Research (KAIR) members
Postdoc
- Dr. Aleksander Holynski (with Alexei Efros)
- Dr. Qianqian Wang (with Alexei Efros)
- Dr. Lea Müller (with Jitendra Malik)
- Dr. Tyler Bonnen (with Jitendra Malik and Alexei Efros)
Graduate Students
- Hang Gao
- Ruilong Li
- Vongani Maluleke (with Jitendra Malik)
- Ethan Weber
- Justin Kerr (with Ken Goldberg)
- Brent Yi (with Yi Ma)
- Chung Min Kim (with Ken Goldberg)
- David McAllister
- Hongsuk Choi
- Visiting PhD student: Songwei Ge
- Visiting PhD student: Haven (Haiwen) Feng
5th year MS students
- Gina Wu
Alumni
Former PhD Students- Dr. Vickie Ye, now at Anthropic
- Dr. Evonne Ng (with Trevor Darrell), now at Meta Reality Labs
- Dr. Shubham Goel (with Jitendra Malik), now at Avataar
- Dr. Matt Tancik (with Ren Ng), now at Luma AI
- Prof. Georgios Pavlakos, now an assistant professor at UT Austin
- Jake Austin (5th yr MS, now PhD student at MIT)
- Frederik Warburg (visiting student from Technical University of Denmark Fall 2022 - Spring 2023)
- Alex Yu, (undergraduate 2020-2022) now co-founder @ Luma AI
- Micael Tchapmi, (visitor 2020-2021) now MS student @ Stanford
- Ze (Edward) Ma, (visitor 2020-2021) now MS Student @ Columbia
- Jason Y. Zhang (undergraduate 2019-2020) now PhD student @ CMU
- Xin Qin (undergraduate 2018-2019) now PhD student @ USC
Libraries


Papers
I'm slowly updating the paper list! those without thumbnail are WIP. Checkout the project pages! See google scholar for latest updates.|
Continuous 3D Perception Model with Persistent State |
|
|
Decentralized Diffusion Models |
|
|
|
Reconstructing People, Places, and Cameras |
|
Estimating Body and Hand Motion in an Ego-Sensed World |
|
|
Shape of Motion: 4D Reconstruction from a Single Video |
|
|
MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos Is this video of mochi on a walk? Yes! MegaSam FTW |
|
|
Toon3D: Seeing Cartoons from New Perspectives |
|
|
Agent-to-Sim: Learning Interactive Behavior Models from Casual Longitudinal Videos |
|
|
Spatial Cognition from Egocentric Video: Out of Sight, Not Out of Mind |
|
|
|
gsplat: An Open-Source Library for Gaussian Splatting |
|
SOAR: Self-Occluded Avatar Recovery from a Single Video in the Wild |
|
|
Synergy and Synchrony in Couple Dances |
|
|
Rethinking Score Distillation as a Bridge Between Image Distributions |
|
|
Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction |
|
|
NeRF-XL: Scaling NeRFs with Multiple GPUs |
|
|
Garfield: Group Anything with Radiance Fields |
|
|
Reconstructing Hands in 3D with Transformers |
|
|
Nerfiller: Completing Scenes via Generative 3D Inpainting |
|
Generative Proxemics: A Prior for 3D Social Interaction from Images
|
|
|
|
The More You See in 2D the More You Perceive in 3D |
LERF-TOGO: Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
|
|
Differentiable Blocks World:
Qualitative 3D Decomposition by Rendering Primitives
|
|
Humans in 4D: Reconstructing and Tracking Humans with Transformers
|
|
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
|
|
LERF: Language Embedded Radiance Fields
|
|
👻Nerfbusters🧹: Removing Ghostly Artifacts from Casually Captured NeRFs |
|
|
NerfAcc: Efficient Sampling Accelerates NeRFs
|
Nerfstudio: A Modular Framework for Neural Radiance Field Development |
|
Decoupling Human and Camera Motion from Videos in the Wild
|
|
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
|
|
On the Benefits of 3D Pose and Tracking for Human Action Recognition
|
|
Monocular Dynamic View Synthesis: A Reality Check
|
|
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
|
|
The One Where They Reconstructed
3D Humans and Environments in TV Shows |
|
TAVA: Template-free Animatable Volumetric Actors |
|
Studying Bias in GANs through the Lens of Race |
|
Plenoxels: Radiance Fields without Neural Networks
|
|
Deformable Sprites for Unsupervised Video Decomposition |
|
Tracking People by Predicting 3D Appearance, Location & Pose |
|
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion |
|
Human Mesh Recovery from Multiple Shots |
|
Differentiable Gradient Sampling for Learning Implicit 3D Scene Reconstructions from a Single Image |
|
Tracking People with 3D Representations |
|
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
|
|
PlenOctrees for Real-time Rendering of Neural Radiance Fields
|
|
|
Reconstructing Hand-Object Interactions in the Wild
|
AI Choreographer: Music Conditioned 3D Dance Generation with AIST++ |
|
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control |
|
KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control |
|
pixelNeRF: Neural Radiance Fields from One or Few Images |
|
De-rendering the World's Revolutionary Artefacts |
|
|
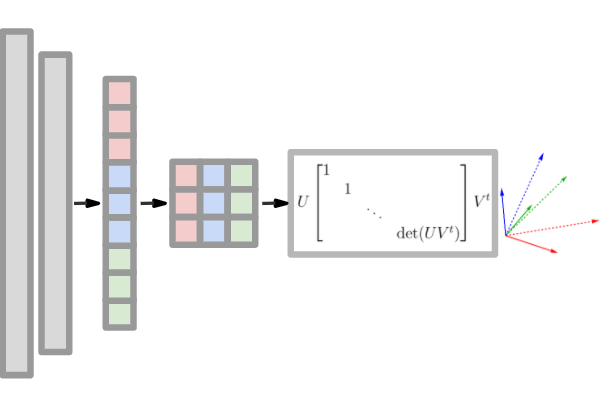
An Analysis of SVD for Deep Rotation Estimation |
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild |
|
Shape and Viewpoint without Keypoints |
|
Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture from Images "In the Wild" |
|
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization |
|
Predicting 3D Human Dynamics from Video |
|
Learning 3D Human Dynamics from Video |
|
|
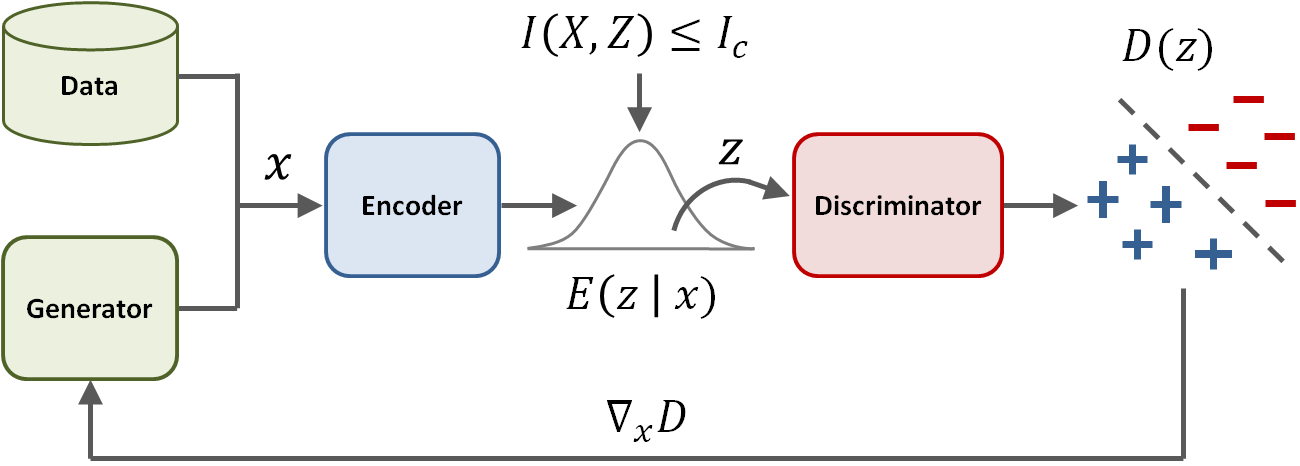
Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow |
|
SFV: Reinforcement Learning of Physical Skills from Videos |
|
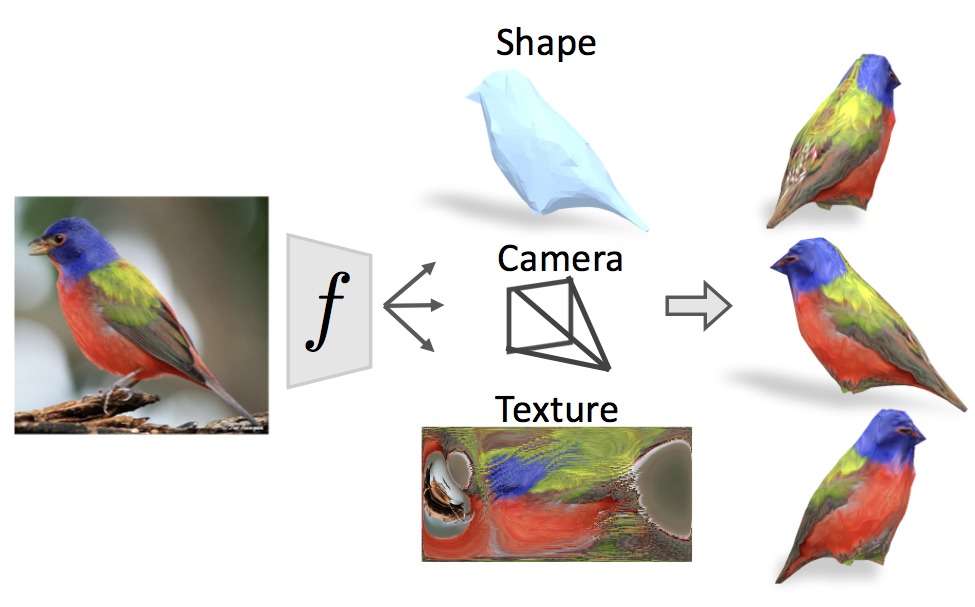
Learning Category-Specific Mesh Reconstruction from Image Collections |
|
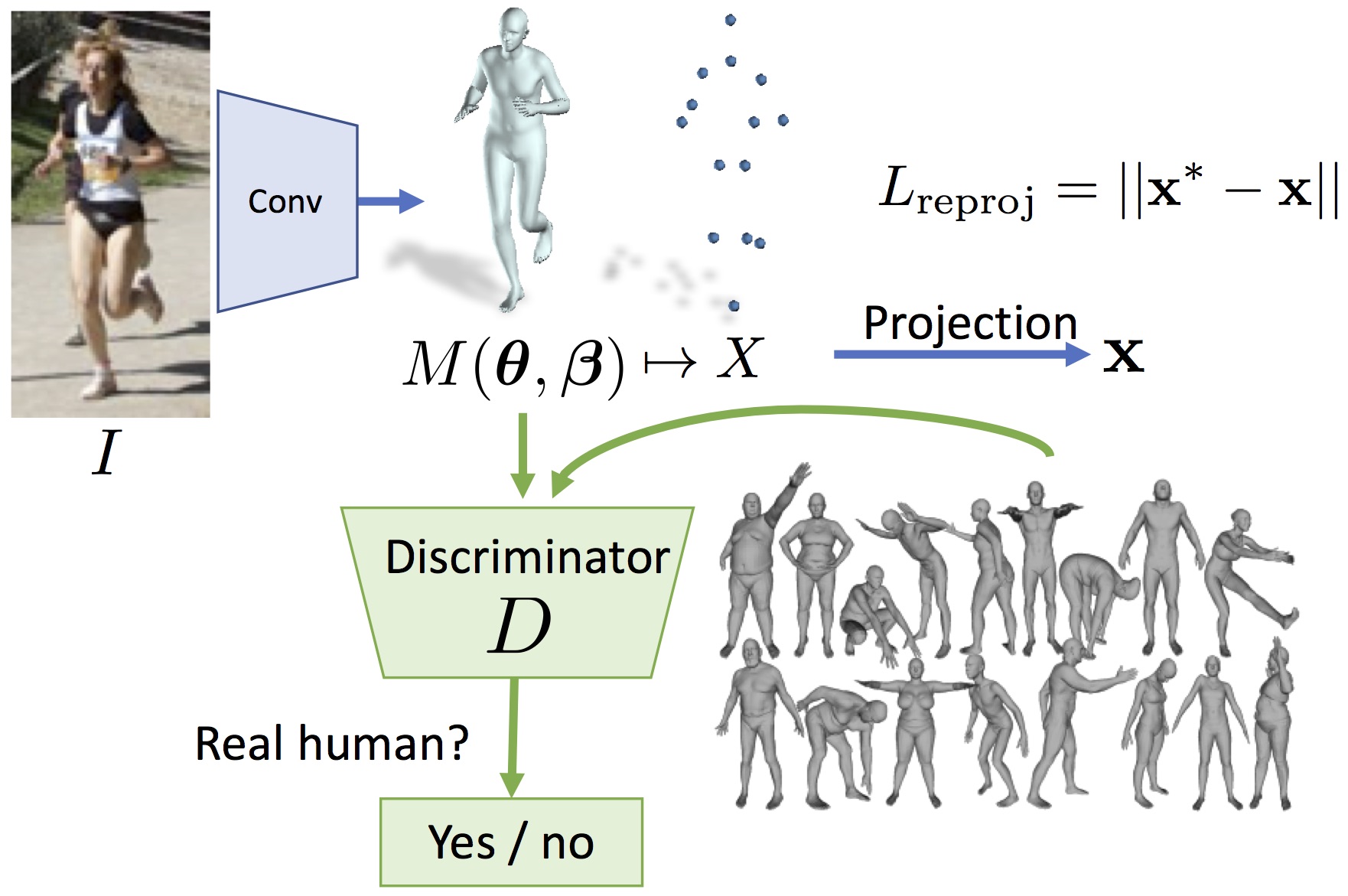
End-to-end Recovery of Human Shape and Pose |
|
SfSNet : Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’ |
|
Lions and Tigers and Bears: Capturing Non-Rigid, 3D, Articulated Shape from Images |
|
Towards Accurate Marker-less Human Shape and Pose Estimation over Time |
|
3D Menagerie: Modeling the 3D shape and pose of animals |
|
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
|
|
WarpNet: Weakly Supervised Matching for Single-View Reconstruction |
|
Learning 3D Deformation of Animals from 2D Images |
|
Locally Scale-invariant Convolutional Neural Network |
|
Affordance of Object Parts from Geometric Features |
|
Dog Breed Classification Using Part Localization
|





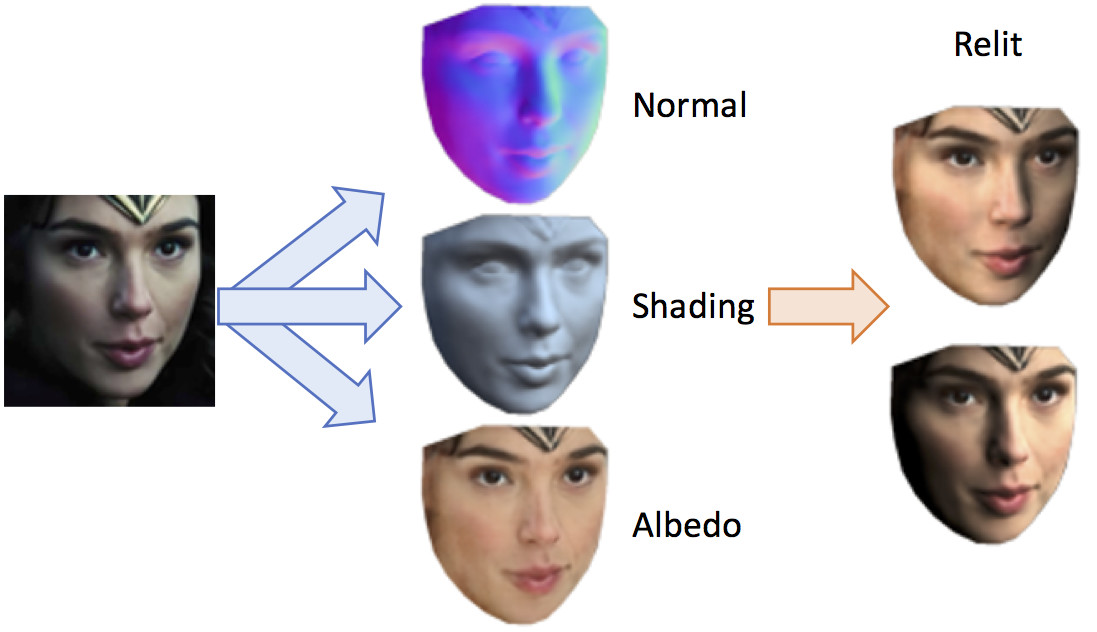

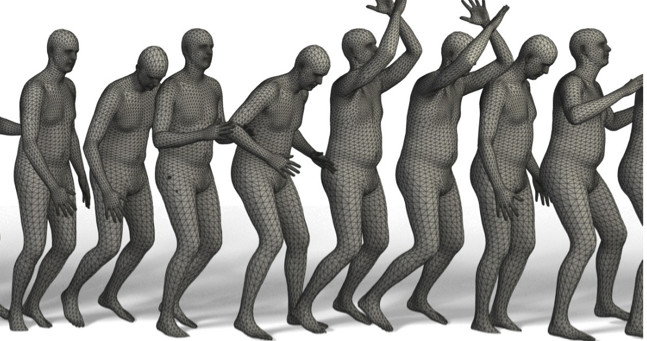
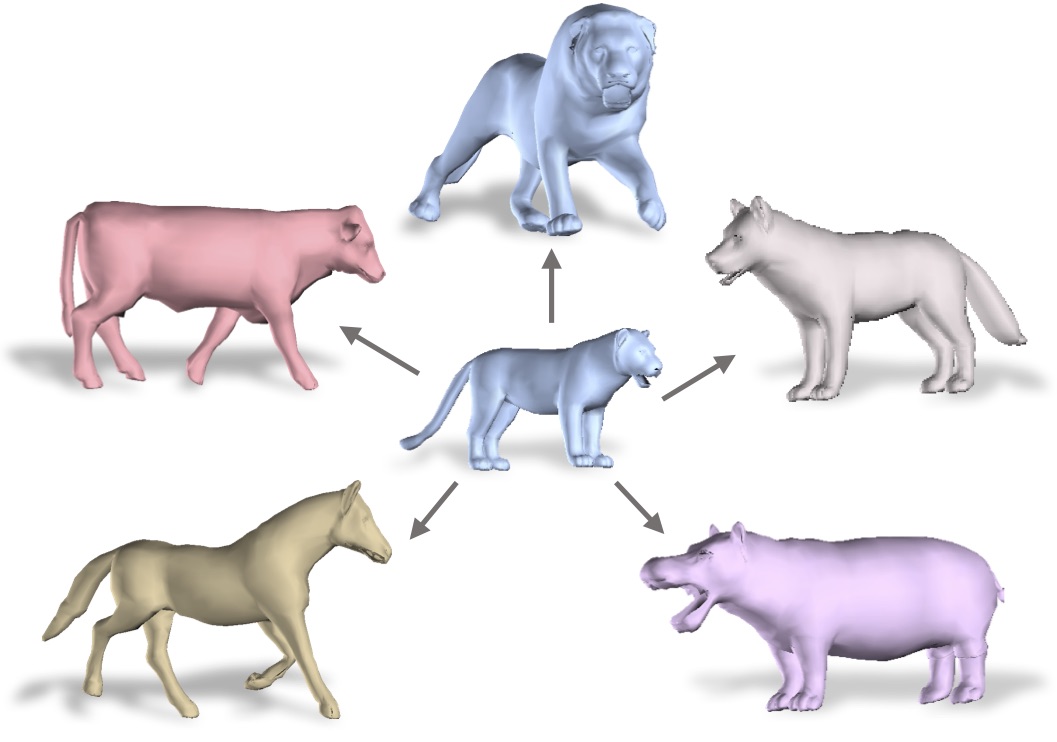



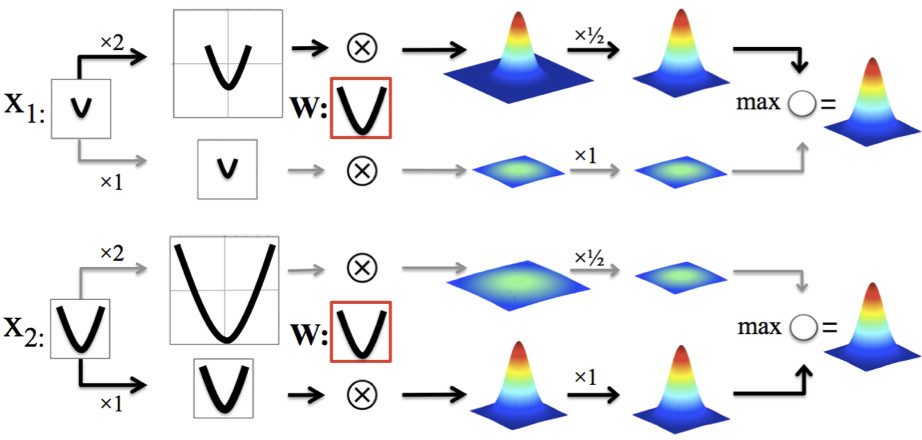

Thesis
Single-View 3D Reconstruction of Animals
Angjoo Kanazawa
Doctoral Thesis, University of Maryland, August 2017
[pdf]
[slides]
Teaching
- Co-Instructor: UC Berkeley CS180 Fall 2023 Introduction to Computer Vision and Computational Photography
- Instructor: UC Berkeley CS294-173 Spring 2023 Learning for 3D Vision
- Co-Instructor: UC Berkeley CS194-26/294-26 Fall 2021 Introduction to Computer Vision and Computational Photography
- Co-Instructor: UC Berkeley CS184/284a Spring 2021 Foundations of Computer Graphics
- Instructor: UC Berkeley CS294-173 Fall 2020 Learning for 3D Vision
Teaching Assistant: UMD CMSC 421 Spring 2012 Introduction to Artificial Intelligence
Teaching Assistant: UMD CMSC 131 Fall 2011 Object-Oriented Programming I
Teaching Assistant: NYU CSCI-UA.0101,0103, Fall 2008, Spring 2009 Introduction to Computer Science I, II
Misc
- I grew up in Kobe, Japan. In Japanese, my name is written as: 金沢 央珠