Tracking People by Predicting 3D Appearance, Location & Pose
CVPR 2022
Tracking People by Predicting 3D Appearance, Location & Pose
CVPR 2022
Abstract
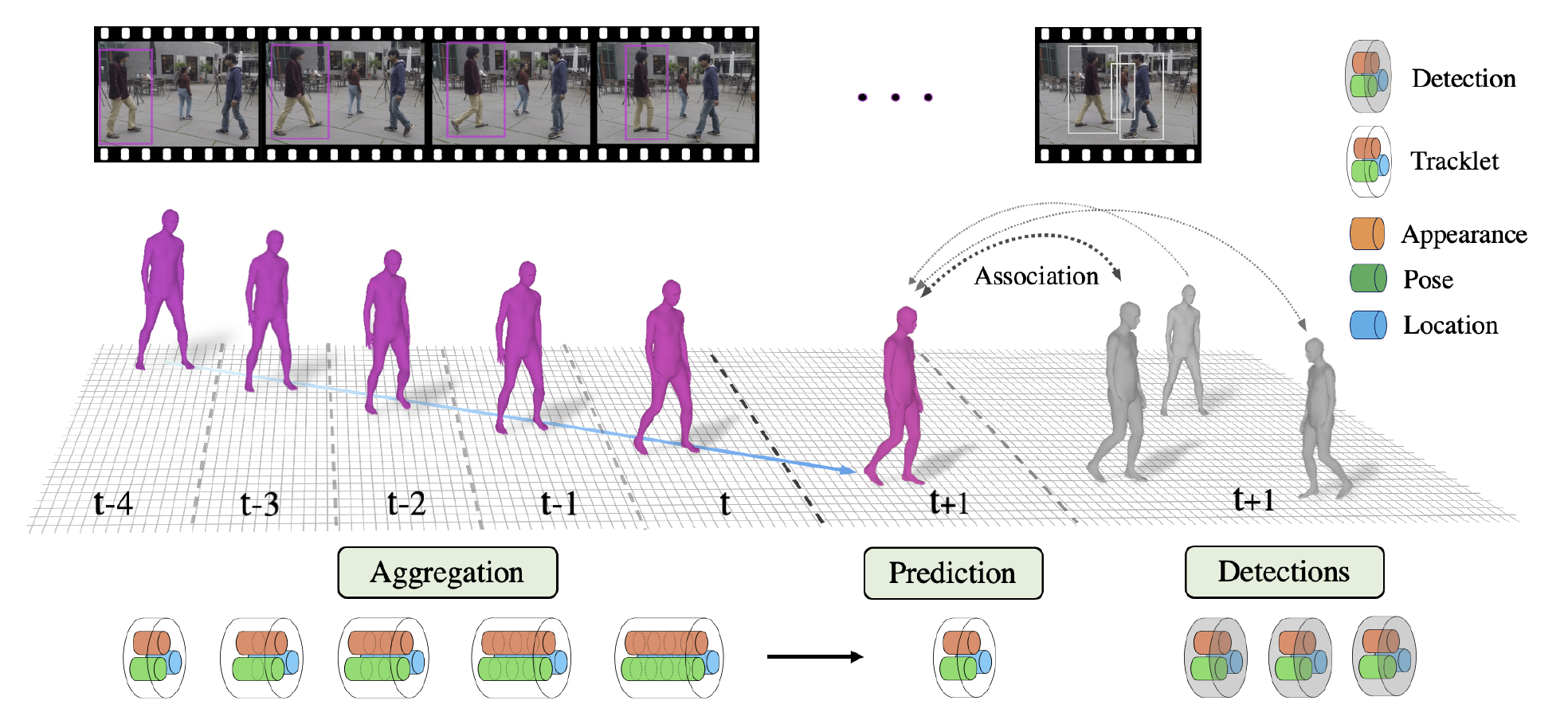
In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.
Citation
Acknowledgements
This work was supported by ONR MURI (N00014-14-1-0671), the DARPA Machine Common Sense program, as well as BAIR and BDD sponsors.

