This website introduces a new mathematical framework for two related classical problems in statistical learning: data clustering and data classification. The basic idea is to cast data clustering or classification as a (lossy) data compression problem. By minimizing the coding length of the data, the resulting clustering and classification solutions are provably optimal and the proposed algorithms are extremely simple, efficient, and robust. They can achieve the state of the art clustering and classification results, especially for high-dimensional data such as images or gene expression data. This page gives a visual introduction to some representative problems that can be solved by this new method. Please click the links at left for a basic introduction to the new approach, or complete technical details in the reference papers, or sample code for all the algorithms, or implementation details on some real-world applications.
Given noisy data with multiple structures, group the data into simpler components:
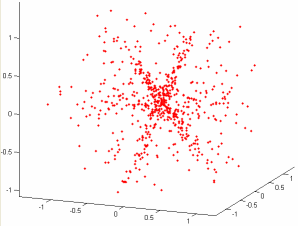 Input: Multivariate mixed data
|
 Output: Subspace-like clusters |
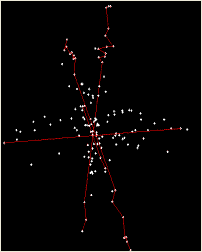 Clustering Mixed Data
(.avi, click to view) |
Real data such as images and videos often have such complicated, mixed structure. Segmentation breaks the image or video into smaller, simpler pieces making it easier to represent, understand or process:
Original image
|
Segmentations at three different scales
|




You can find more details about our solution derived from this framework for image segmentation at our Natural Image Segmentation page or our paper, Segmentation of Natural Images by Texture and Boundary Compression, in the references page.
Given a set or training examples whose identity is known, determine the identity of a new sample:
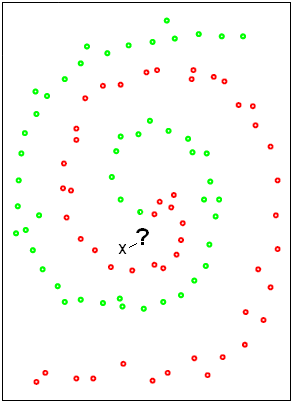 Training examples ( o and o ) and a Test example ( x ) whose identity is unknown |
 Decision boundary between two classes Test sample is classified as ( o ) |
One of the most prominent applications of this fundamental problem is in automatic face recognition, where the training examples images of human faces, taken under varying expression, pose, or lighting conditions. The test example is an image of a face, possibly taken under different pose, expression or lighting condition. The task is to identify which of the individuals in the training database is pictured in the test image:
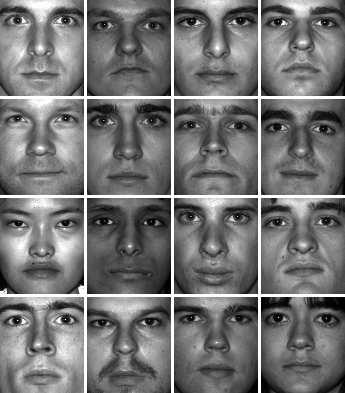 Training examples |
 Test image
|
 Classification Result
|
To read more about the classification problem and its solution, please refer to our introduction page, or to our paper, Classification via Minimum Incremental Coding Length (MICL) on the references page.
Credits
This website is developed and maintained by the research group of professor Yi Ma at the University of Illinois at Urbana-Champaign.
This material is based upon work supported by the National Science Foundation under Award No. IIS-0347456, CRS-EHS-0509151, and CCF-TF-0514955, and by the Office of Naval Research, under Award No. N0001405-1-0633. Any opinions, findings, and conclusions or recommendations expressed in this publication are those of the authors and do not necessarily reflect the views of the National Science Foundation or Office of Naval Research.
Please direct all questions and comments about this website to the webmaster: John Wright (jnwright@uiuc.edu).