We first demonstrated our system at the SIGGRAPH Conference from August 3-8, 1997 [1]. An estimated 5000 people over 6 days used our system (approximately two new users per minute, over 42 hours of operation). The goal of the system in this application was to identify the 3-D position and size of a single user's head in the scene, and apply a distortion effect in real-time only over the region of the image containing the user's face. The distorted image was then displayed on the virtual mirror screen. The system tracked the user while he or she was in the frame, and then switched to a new user.
Qualitatively, the system was a complete success. Our tracking results were able to localize video distortion effects on the user's face, and overall the system was interesting and fun for people to use. Figure 6 shows a typical final image displayed on the virtual mirror. The system performed well with both single users and crowded conditions; the background environment was quite visually noisy, with many spurious lighting effects being randomly projected throughout the conference hall, including onto the people being tracked by our system.
 |
We quantitatively evaluated the performance of our system using three off-line datasets: a set of stills captured at SIGGRAPH to evaluate detection performance, a set of stills of users in our laboratory, and a set of appearance statistics gathered from users in our laboratory who interacted with the system over several days. (Unfortunately we were not able to obtain observations of the same users across multiple days at the SIGGRAPH demonstration.)
We collected stills of users interacting with our system every 15 seconds
over a period of 3 hours at the SIGGRAPH demonstration. At each sample point
we captured both a color image of the scene and a greyscale image of the
output of the range module after disparity smoothing. We discarded
images with no users present, yielding approximately 300 registered
color/range pairs. Figure 5 shows examples of the collected
stills. We also collected a similar set of approximately 200 registered
range/color stills of users of the system while on display in our laboratory,
similar to the images in Figures 2 and 3(a).
Table 1 summarizes the single-person detection results we obtained on
these test images. A correct match was defined when the corners of the
estimated face region were sufficiently close to manually entered ground truth
(within ![]() of the face size). Overall, when all modules were
functioning, we achieved a success rate of 97%; when the color and/or
face detection module was removed, performance was still above 93%,
indicating the power of the range cue for detecting likely head locations.
of the face size). Overall, when all modules were
functioning, we achieved a success rate of 97%; when the color and/or
face detection module was removed, performance was still above 93%,
indicating the power of the range cue for detecting likely head locations.
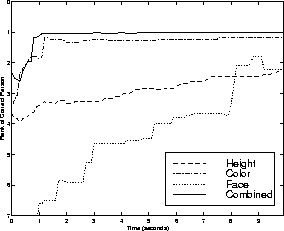
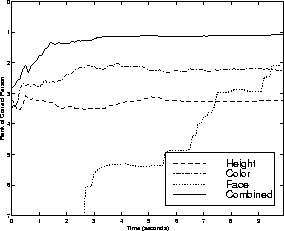
To evaluate our longer term tracking performance we used statistics gathered from 25 people in our laboratory who visited our display several times on different days. People's hairstyle, clothing, and the exterior illumination conditions varied between the times data were collected. We tested whether our system was able to correctly identify users when they returned to the display. In general, our results were better for medium term tracking (intra-day) than for long term (inter-day) tracking, as would be expected. Table 2 shows the extended tracking results: the correct classification percentage is shown for each modality and for the combined observations from all modes. This table reflects the recognition rate using all of the data from each short-term tracking session: on average, users were tracked for 15 seconds before short-term tracking failed or they exited the workspace.
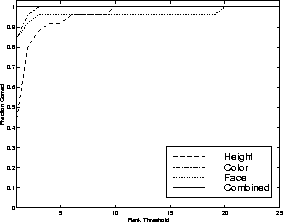
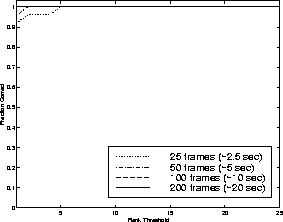
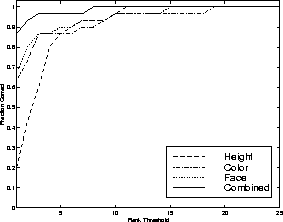
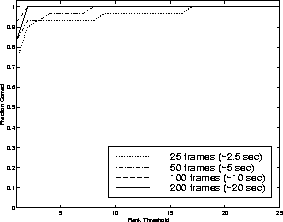
By integrating modes we were able to correctly establish correspondences between tracked users in all of the medium-term cases, which typically involved temporal gaps between 10 and 100 seconds. In the long-term cases, which typically reflected gaps of one day, integrated performance was 87%. A more complete description of medium- and long-term performance is shown in Figure 7 and Figure 10, respectively. These figures show the recognition rate vs rank threshold, i.e., the percentage of time the correct person was above a given rank in the ordered likelihood list of predicted users. We also measured our performance over time: Figures 8 and 11 compare the performance versus rank threshold at 4 different times during each testing session. Here we show only the multi-modal results; as expected, identification becomes more reliable over time as more data is collected. Figures 9 and 12 show the rank of the correct person over time, averaged across all test sessions; correct identification (average rank equals one) is almost always achieved within one second in the medium-term case, and within three seconds in the long-term case.
We draw two main conclusions from the detection results; first, that range data is a powerful cue to detecting heads in complex scenes. Second, integration is useful: in almost every case, the addition of modules improved system performance. Performance was generally high, but individual module results varied considerably across datasets. In particular the face pattern module fared relatively poorly on the SIGGRAPH dataset. We believe that this is largely due to the small size and poor illumination of many of the faces in these images. Additionally, in both datasets our application encouraged people to make exaggerated expressions, which was beyond the scope of the training for this module.
In contrast, for extended tracking it is clear from these results that the face pattern is the most valuable of the three modes when we consider all the data available during the session. Face pattern data is most discriminating at the end of the test session; however, the other modalities are dominant early in the session. The face detection module operates more slowly than the other modes, so the face pattern data is not available immediately and accumulates at a slower rate. Therefore, in the first few seconds the overall performance of the extended tracking system is due primarily to color and height data, and far exceeds the performance based on face pattern alone.
 |
 |
 |
 |