|
I am a fourth-year PhD student in the Sky lab (formerly RISE Lab), advised by Prof. Ion Stoica. In my past life, I was a research assistant at Carnegie Mellon University, Pittsburgh where I worked on FPGA acceleration for computer vision and AR/VR with James C. Hoe and Anthony Rowe. Prior to that, I earned my Bachelors from IIIT Hyderabad, India. |

|
|
|

|
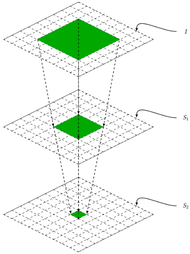
Melih Elibol, Vinamra Benara, Samyu Yagati, Lianmin Zheng, Alvin Cheung, Michael I. Jordan, Ion Stoica 2021-Ongoing NumS is a Numerical computing library for Python that Scales. It is a distributed memory array abstraction that matches much of the syntax of the NumPy API, extending NumPy to scale horizontally, as well as provide inter-operation parallelism. |
|
Suresh Purini, Vinamra Benara, Ziaul Choudhury, Uday Bondhugula ACM SIGPLAN International Conference on Compiler Construction (CC), Feb 2020 The power and area savings while performing arithmetic operations on fixed-point data type are well known to be significant over using floating-point data type. PolyMage-HLS is the FPGA backend of PolyMage DSL where data is stored at each stage of a pipeline using a fixed-point data type (alpha, beta ) where alpha and beta denote the number of integral and fractional bits. In this work, we propose an interval-arithmetic based range analysis algorithm to estimate the number of bits required to store the integral part of the data at each stage of an image processing pipeline. The analysis algorithm uses the homogeneity of pixel signals at each stage to cluster them and perform a combined range analysis. We show that interval/affine arithmetic based techniques fail to take into account correlated computations across stages and hence could lead to poor range estimates. These errors in range estimates accumulate across stages, especially for iterative programs, such as Horn-Schunck Optical Flow, resulting in estimates nearly unusable in practice. Then, we propose a new range analysis technique using Satisfiability Modulo Theory (SMT) solvers, and show that the range estimates obtained through it are very close to the lower bounds obtained through profile-driven analysis. We evaluated our bitwidth analysis algorithms on four image processing benchmarks listed in the order of increasing complexity: Unsharp Mask, Down-Up Sampling, Harris Corner Detection and Horn-Schunck Optical Flow. The performance metrics considered are quality, power, and area. For example, on Optical Flow, the interval analysis based approach showed an 1.4x and 1.14x improvement on area and power metrics over floating-point representation respectively; whereas the SMT solver based approach showed 2.49x and 1.58x improvement on area and power metrics when compared to interval analysis. |

|
Designed an FPGA accelerated headset prototype that aims to solve the motion sickness problem with current AR/VR headsets. It runs at 240 FPS and currently has a motion-to-photon latency below 8 ms. To the best of our knowledge, it is the world's first prototype with such a low latency. I am working towards reducing it to 4 ms. We aimed to solve it by accelerating the post render warping (PRW) on an FPGA. The whole point of using the FPGA here is to have a very low latency end to end design. Our display is a DMD (Digital Micromirror Device). I drive this directly from the FPGA via HDMI. After a 360-degree scene is rendered, the orientation of the head is provided by the IMU (Inertial Measurement Unit). Based on that and the field of view, the scene is cropped and warped. We used a Zynq board (Xilinx ZedBoard) for this purpose. The IMU talks to the arm core of the device via SPI and Kalman filtering is done there. A new rotation matrix is obtained from the IMU at 100 Hz and is fed to the PRW pipeline in the FPGA. The setup is in a development stage and currently works with static scenes and there is WIP to integrate the system with an OptiTrack tracker which tracks the location of the user in the 3-dimensional space. |
|
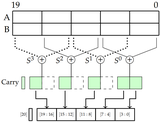
Vinamra Benara, Suresh Purini IEEE Computer Society Annual Symposium on VLSI (ISVLSI), July 2016 Approximate computing techniques have paved new paths to get substantial improvement in speed and power efficiency by making a trade-off with the accuracy of computations in inherently error tolerant applications, like from image and video processing domains. The accuracy requirements of various applications can differ from each other. Even within a same application different computations can have different accuracy requirements which can vary over time and upon user requirements. Accuracy configurable arithmetic circuits are essential for these reasons. Such techniques proposed earlier in the literature (ACA) work by improving the accuracy over several pipeline stages. However, those techniques suffer from the drawback that the corrections being made in the initial pipeline stages are small in magnitude as they are performed from the least significant bit position. In this paper, we propose a new correction technique -Accurus wherein we start from the most significant bit resulting in fast convergence of the result towards the accurate one. We used our approximate adder circuit in a Gaussian Blur filter which is then applied to an image. After one stage of correction, we achieved a peak signal to noise ratio of 40.90 dB when compared with 25.59 dB obtained using the previous well-known technique (ACA). |
|
(last updated August 2022)
|