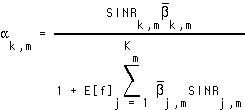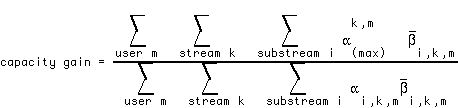
Paul Haskell, David G. Messerschmitt, and Louis Yun
Department of Electrical Engineering and Computer Sciences
University of California at Berkeley
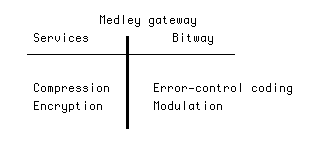
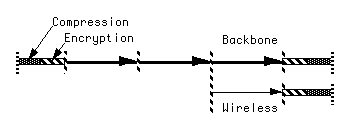
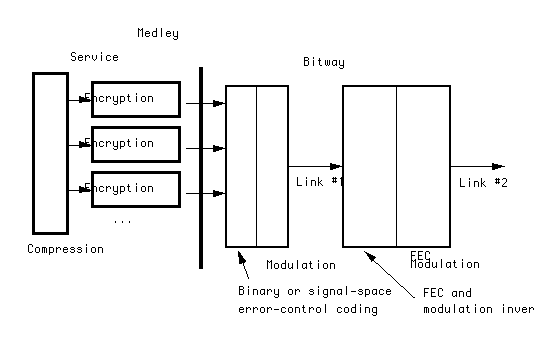
Most of our attention is focused on the signal processing technologies in a multimedia network, including compression, modulation, forward error-correction coding (FEC), and encryption, as well as limited attention to other elements that interact with signal processing (such as protocols). From a networking perspective, we define as signal processing those functions that modify or hide basic syntactical and semantic components of a bit stream payload, as opposed to those functions that are oblivious to the payload bits (such as protocols, routing, etc.).
In treating these issues, it is important to identify the objectives that are to be achieved. We can list those objectives relevant to this chapter as follows:
Another important consideration is complexity management [4]. The internet protocols have managed to contain complexity by partitioning most functionality within the terminals, and keeping the internet layer relatively simple and state-free. As a result, a rich suite of applications have been deployed swiftly. In contrast, the public telephone network, with a relatively limited set of services based on 64 kb/s circuits and a centralized control model, is straining at the limits of complexity within the switching-node software. Because the central-control telephone model is not extensible to achieving the flexibility required in future multimedia networks, distributed "intelligent networking" approaches to control are being deployed [5], and even more sophisticated approaches are being considered [6][7]. The internet model also becomes considerably more complicated when extended to CM services, due to the need for resource reservations and multicast connections [2]. Careful attention should be paid to complexity management from the outset.
In this chapter, we propose some architectural principles and discuss their implications to the constituent signal processing technologies listed above. These suggest many new requirements for the signal processing, and present opportunities to signal processing researchers and developers for years to come. A more general perspective on the convergence of communications and computing as embodied in multimedia networking is available [8][9], as is a treatise on some of the societal impacts [10].
Compression removes signal redundancy as well as signal components that are subjectively unimportant, so as to increase the traffic-carrying capacity of transmission links within the bitway layer. Compression typically offers a trade-off between a signal's decoded fidelity and its transmitted bandwidth, and often has the side effect of increasing the reliability requirements (loss and corruption) for an acceptable subjective quality. Compression can be divided into two classes: signal semantics based (such as conventional video and audio compression), and lossless, which processes a bit stream without cognizance of the underlying signal semantics. The compression typically has to make some assumptions about the bitway characteristics, such as the relative importance of rate and reliability (see Section 2.5).
Encryption reversibly transforms one bit stream into another such that a reasonable facsimile of the original bit stream is unavailable to a receiving terminal without knowledge of appropriate keys [13]. Encryption is one component of a conditional access system, with which a service provider can choose whether and when any individual receiver can access the provided service, and is also useful in insuring privacy. It precludes any processing of a bit stream, as it hides the underlying syntactical and semantic components, except in a secure server than has keys available to it. It also increases susceptibility to bit errors and synchronization failures, as discussed in Section 4.1.
Forward error-correction coding (FEC) adds a controlled redundancy so that transmission impairments such as packet loss or bit errors can be reversed. We distinguish binary FEC techniques from signal-space techniques. Binary FEC is applied to a bitstream and produces a bitstream; examples include Reed-Solomon coding and convolutional coding. Binary FEC has the virtue of flexibility, as it can be applied on a network end-to-end basis in a manner transparent to the individual links. FEC can be combined with other techniques, such as interleaving (to change the temporal pattern of errors) and retransmission (to repeat lost or corrupted information), if the temporal characteristics or error mechanisms are known. Signal-space coding, on the other hand, is tightly coupled with the modulation method (used to encode bits onto waveforms) and the physical characteristics of the medium and is often accompanied by soft decoding. Examples include lattice and trellis coding. It is usually custom-tailored to the physical characteristics of each link, and as a result can offer significantly higher performance. Wireless link modulation methods often incorporate power control and temporal and spatial diversity reception.
Figure 3 illustrates some fundamental syntactical constraints that we should keep in mind while designing a network architecture for CM services:
The best trade-off between signal fidelity and bandwidth appropriate for a high-speed wired sublink may be very unreasonable for a wireless link. Frequently this motivates system designs that include transcoders within the network, as with the IS-54 digital cellular system described in Section 2.5. Of course, if decompression and recompression are performed at transcoders within the network, there is a requirement for a secure server to perform decryption and encryption.
However it is with FEC that the existence of multiple heterogeneous subnetworks complicates CM system design the most. It would be simplest to provision a single end-to-end FEC system across a heterogeneous network; however, the efficiencies of closely coupled error correction coding, suitably-designed modulation, and specific subnet characteristics may be too significant to pass up in some cases. Section 2.5 and Section 5.1 discuss this further.
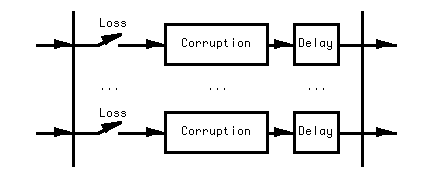
Data networks do not make a distinction between loss and corruption, since a packet that is corrupted is useless and hence is discarded. CM services can tolerate some level of loss and corruption without undue subjective impairment, especially if there is appropriate masking built into the signal decoders. This is fortunate, since absolute reliability such as afforded by data networks requires retransmission mechanisms, which can introduce indeterminate delay, often excessive to interactive applications like telephony and video conferencing. Another distinct characteristic of CM services is that loss and corruption are different effects. Lost data must be masked, for example in video by repeating information from a previous frame, or in audio substituting a zero-level signal. Under some circumstances it is possible to make good use of corrupted information, for example by displaying it as if it were correct. The resulting subjective impairment may be less severe that if the corrupted data were discarded and masked.
Some CM compression standards, generally those presuming a reliable transport mechanism (such as MPEG video [14][15][16][17]) discard corrupted data and attempt to mask the discarded information. Other standards -- those designed for a very unreliable transport (such as the voice compression in digital cellular telephony [18] and video compression designed for multiple access wireless applications [19]) -- use corrupted data as if it were error-free, and minimize the subjective impact of the errors. An important research agenda for the future is audio and video coding algorithms that are robust to loss and corruption introduced by wireless networks, recognizing that these effects are more severe than in backbone networks.
CM services are real-time, meaning that they require transport-delay bounds. However, there is a wide variation in delay tolerance depending on the application. For example, a video-on-demand application will be relatively tolerant of delay, whereas it is critical that transport delay be very small (on the order of 50 msec or so) for a multimedia editing or video conferencing application. Much recent attention is focused on achieving bounded delay through appropriate resource reservation protocols [2][20][21]. Given this wide range of delay tolerance, it is clear that the highest traffic capacity can only be obtained by segmenting services by delay, coupled with delay-cognizant scheduling algorithms within the bitway statistical multiplexers.
Audio and video services are usually considered to be synchronous, implying that network transport jitter is removed by buffering before reconstructing the audio or video. For the special case of voice, it is possible to change the temporal relationship of talkspurts somewhat without any noticeable effect, but video display is organized into periodic frames (at 24, 25 or 30 frames/second), and all information destined for a frame must arrive before it can be displayed. (We make an alternative proposal in Section 5.3.)
Packets arriving after some prescribed delay bound are usually considered to be lost, as if they did not arrive at all.[2] This illustrates another important characteristic of CM services, the existence of stale information that will be discarded by the receiver if it does not arrive in timely fashion. As another example, the bitway may be working feverishly to deliver a pause-frame video when the motion suddenly resumes. Any state residing in the bitway relevant to the pause-frame will not be used at the receiver. The purging of stale information within the bitway layer will increase traffic capacity.
If JSCC is to be applied to an integrated services multimedia network, we have to deal with complications like the fact that a single source coder must be able to deal with a variety of transport links (broadband backbone and wireless in particular), the concatenation of heterogeneous transport links, and multicast connections with common source representations flowing over heterogeneous links in parallel. In this environment, it is appropriate to consider loosely coupled JSCC, which is the only variety we pursue in this chapter. Loosely coupled JSCC attempts to abstract those attributes of the source and the channel that are most relevant to the other, and to make those attributes generic; that is, broadly applicable to all sources and channels and not tightly coupled to the specific type.
Loosely coupled JSCC is thus viewed differently from the perspective of the "source" and the "channel", where channel is usually taken to mean a given physical-layer medium, but which we take here to mean the entire bitway network. From the perspective of the bitway, JSCC ideally adjusts the allocation of network resources (buffer space, bandwidth, power, etc.) to maximize the network traffic capacity subject to a subjective quality objective. From the perspective of the source, JSCC ideally processes the signal in such a way that bitway network impairments have minimal subjective effect, subject to maximizing the network's traffic capacity. This suggests that the source coding must take account of how the bitway allocates resources, and the effect this has on end-to-end impairments as well as traffic capacity, and conversely the bitway needs to know the source coding strategy and the subjective impact of the bitway resource allocations. However, to embed such common knowledge would be a violation of the loosely coupled assumption, creating an unfortunate coupling of source and channel that precludes further evolution of each. Rather, we propose a model in which the source is abstracted in terms of its bitrate attributes only, and the bitway is abstracted in terms of its QoS attributes only. The benefits of JSCC can still be achieved with this limited knowledge, but only if the source and channel are allowed to negotiate at session establishment. During negotiation, each of the source of channel is fully cognizant of its internal characteristics, and can influence the other only through a give-and-take in establishing the rate and QoS attributes, taking into account some measure of cost. The substream architecture discussed in Section 3.0 will increase the effectiveness of loosely coupled JSCC.
A simple example of JSCC is compression [33]. The classical goal of compression is to minimize bit rate, which is intended to maximize the traffic capacity of the network without harming the subjective quality appreciably. However, minimizing the bit rate (say in the average sense) is simplistic, because traffic capacity typically depends on more than average bit rate. To cite several examples:
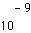 to
to 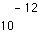 (depending on the application) [34][35]. While this is feasible in storage, fiber, and broadcast wireless applications (such as terrestrial HDTV [33]), this is likely not feasible in multiple access wireless applications[4]. (Voice standards intended for multiple access channels and mobile receivers with fading generally assume a worst-case error rate in the range of
(depending on the application) [34][35]. While this is feasible in storage, fiber, and broadcast wireless applications (such as terrestrial HDTV [33]), this is likely not feasible in multiple access wireless applications[4]. (Voice standards intended for multiple access channels and mobile receivers with fading generally assume a worst-case error rate in the range of 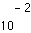 to
to 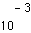 , which is more representative on these types of channels during deep fades [18].) MPEG illustrates the difficulty in designing compression standards with sufficient flexibility and scalability to accommodate a variety of transport scenarios.
, which is more representative on these types of channels during deep fades [18].) MPEG illustrates the difficulty in designing compression standards with sufficient flexibility and scalability to accommodate a variety of transport scenarios.MPEG-1 is limited not just to low-error-rate bitways, but to low-delay-jitter bitways as well. Fortunately, this limitation was addressed during the design of MPEG-2. The MPEG-2 Real-Time Interface (RTI) permits system designers to choose the maximum delay jitter expected in their systems; given this value, the RTI specifies how decoders can handle the specified jitter. The generic nature of the RTI came about specifically because the MPEG-2 designers wanted to handle delay jitter in a variety of bitways: satellite, terrestrial, fiberoptic, cable, etc. This is an example of transport characteristics influencing compression design. See Section 5.2 for further discussion of MPEG.
The critical role of traffic capacity in wireless access subnets typically results in systems with intricate but inflexible schemes for JSCC, as can be illustrated by a couple of concrete recent examples. These examples also illustrate some of the pitfalls of the coupling of the CM service and the network, and they point to some opportunities to reduce this coupling.
One example is the IS-54 digital cellular telephony standard. This standard uses radio TDMA transport, which due to vehicular velocity is subject to rapid fading. Due to fading, and also in an effort to increase traffic capacity by an aggressive cellular frequency resuse pattern, worst-case error rates on the order of 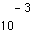 are tolerated (the error rate could be reduced at the expense of traffic capacity of course). The speech is aggressively compressed, and as a result the error susceptibility is increased, particularly for a subset of the bits. Therefore, the speech coder bits are divided into two groups, one of which is protected by a convolutional code, and the other is left unprotected. Interleaving is used to spread out errors (which are otherwise grouped at the demodulator output). What do we consider undesirable about this system design? At least a few things:
are tolerated (the error rate could be reduced at the expense of traffic capacity of course). The speech is aggressively compressed, and as a result the error susceptibility is increased, particularly for a subset of the bits. Therefore, the speech coder bits are divided into two groups, one of which is protected by a convolutional code, and the other is left unprotected. Interleaving is used to spread out errors (which are otherwise grouped at the demodulator output). What do we consider undesirable about this system design? At least a few things:
A final example will illustrate an architecture that begins to redress some of these problems. The Advanced Television Research Consortium (ATRC) proposal for terrestrial broadcast TV [36] makes an attempt to separate the design of the video compression from the transport subsystem by defining an intermediate packet interface with fixed-length packets (cells). Above this interface is an adaptation layer which converts the video compression output byte stream into cells, and below this interface the cells are transported by error-correction coding and RF modulation. Much more enlightening is the way in which a modicum of JSCC is achieved. First, the compression algorithm splits its output into two substreams, where, roughly speaking, the more subjectively-important information is separated from the less subjectively important (and a reasonable rendition of the video can be obtained from the first substream).[5] This separation is maintained across the packet interface, and is thus visible to the bitway. The bitway transmits these two substreams via separate modulators on separate RF carriers, where the first substream is transmitted at a higher power level. The motivation for doing so illustrates another important role of JSCC on wireless access links; namely, achieving graceful degradation in quality as the transmission environment deteriorates. In this case, in the fringe reception area the quality will deteriorate because the second substream is received unreliably, but a useful picture is still available based on the first substream. This system illustrates some elements of an architecture that will be proposed later.
The reasons that we include encryption within the services layer are more subtle:
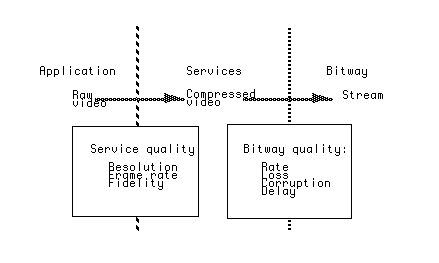
Since the bitway core function is to transport packets, the abstract view should focus on the fundamental packet transport impairments of corruption, loss, and delay. A basic model incorporating these three elements is shown schematically in Figure 5. Often, the service will be interested in the temporal properties of these impairments; that is, a characterization of whether impairments like losses, corruption, or excessive delays are likely to be bunched together, or if they are statistically spread out in time. This issue is discussed further later.

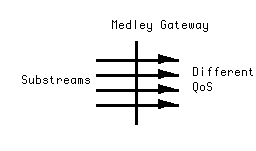
More generally, the service, knowing the QoS to be expected on the substreams, can associate packets with substreams in a way that results in acceptable subjective quality. The bitway, knowing the QoS expectations and rates, can allocate its internal resources, such as buffer capacity, power, etc., in a way that maximizes the traffic capacity. In the absence of the substream structure, the bitway would have to provide the tightest or most expensive QoS requirements to the entire stream in order to achieve the same overall subjective quality.
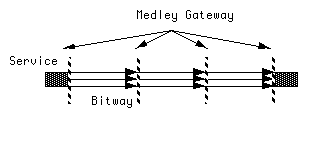
Fortunately, the substream model is consistent with the most important existing protocols. Substreams have been proposed in ST-II, the second-generation Internet Stream Protocol [47]. Version 6 of the Internet Protocol (IP) includes the concept of a flow, which is similar to our substream, by including a flow label in the packet header [48]. ATM networks incorporate virtual circuits (VC), and associate QoS classifications with those VC's, where there is nothing to preclude a single application from using multiple VC's. The notion of separating packets into (usually two) priority classes is often proposed for video [49][50][51], usually with the view toward congestion networks. In particular, a two-level priority for video paired with different classes of service in the transmission has been proposed for broadcast HDTV [36]. We believe that substreams should be the universal paradigm for interconnection of services and bitways for a number of reasons elucidated below, and especially the support of wireless access and encryption. By attaching the name "medley gateway" to such an interface, we are not implying that a totally new gateway function is required. Rather, we propose this as a common terminology applying to these disparate examples of a similar concept.
The distinction between a stream composed of a set of substreams and a set of streams with different QoS requirements is that a stream composed of substreams can have the rate and QoS descriptions of the substreams "linked together." For example, a service could specify that the temporal rate characteristics of all of its substreams are highly correlated (or that two substreams' rates are very negatively correlated)[6]. Also, a service could request "loss priorities" from a bitway by explicitly specifying that packets on one substream should not be discarded while packets on another substream are delivered successfully. Another example is a service that requests one substream be given a higher "delay priority" than another substream, to ensure that packets on the first substream experience less delay than packets on the second.
Combining the bitway and service abstractions, the overall situation is illustrated in Figure 7. Each of a set of substreams receives different QoS attributes and hence a quantitatively different bitway model. As discussed in Section 5.4, this bitway abstraction opens up some interesting new possibilities in the design of services.
In the absence of the substream structure, the bitway would have to provide the tightest or most expensive QoS requirements to the entire stream in order to achieve the same overall subjective quality (and the QoS needs of different packets may vary over several orders of magnitude, e.g. for MPEG video headers vs. chrominance coefficients). Thus, the bitway has the option of exploiting the substream structure to achieve more efficient resource use through JSCC. Critically, substreams are generic and not associated with any particular service (for example audio or video or a specific audio or video coding standard).
The medley gateway model does impose one limitation on JSCC. It does not include a feedback mechanism by which information on the current conditions in the bitway layer can be fed back to affect the services layer. Nor does it allow the flowspec to be time-dependent. One can envision scenarios under which this "closed loop" feedback would be useful. One example is flow control, in which compression algorithms are adjusted to the current information-carrying capacity of a time-varying channel. Another is an adjustment of compression algorithms to the varying bit error rate due to time-varying noise or interference effects. We do not include these capabilities because we question their practicality in the general situation outlined in Section 4.0, where the services layer implementation may be geographically separated from the bitway entity in question, implying an unacceptably high delay in the feedback path. This does raise questions of how to deal with time-varying wireless channels. In this case, we do not preclude feedback within a bitway link, adapting various functions like FEC and power control in an attempt to maintain a fixed QoS.
The multiple substream model of the medley gateway has several characteristics that may particularly require a transport protocol:
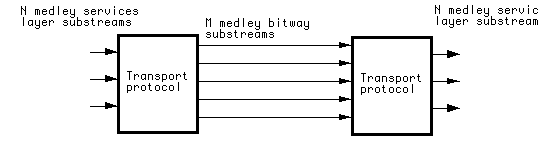
In the loosely coupled JSCC model, we envision a connection establishment flowspec negotiation between service source and sink and bitway. These three entities can iterate through multiple sets of flowspec attributes to find a set that balances service performance and connection cost goals well. For example:
Unfortunately an establishment negotiation in this form is not advisable for multicast connections, because it is not scalable and is likely to be overly complex. The service source would have to negotiate with an unknown number of service sinks and associated bitway entities -- potentially thousands. Further, sinks will typically be joining and leaving the multicast connection during the session, and it is not reasonable to expect that the source will reconfigure (e.g. new compression algorithm or substream decomposition) on each of these events, especially if this requires all other sinks to reconfigure as well. Mobility of receiving terminals raises similar issues.
To avoid this problem, we can envision a different form of configuration for multicast groups, with some likely compromise in performance, inspired by the multicast backbone (Mbone) [52] and RSVP [2]. The service source generates a substream decomposition that is designed to support a variety of bitway scenarios, unfortunately without knowing in advance their details. It also indicates to the bitway (and potential service sinks) information as to the trade-offs between QOS and subjective quality for each substream. Each new sink joining the multicast group subscribes to this static set of substreams based on resources and subjective quality objectives, and this subscription would be propagated to the nearest feasible splitting point. The QOS up to this splitting point would be predetermined, but possibly configurable downstream to the new sink. The resulting compromise -- the bitway QOS to each new sink would be constrained by the QOS to the splitting point established by other sinks -- could be mitigated by allowing a sink to request the addition of bitway resources upstream from the splitting point.
For wireless links, the ability to configure QoS is dependent on assumptions about the propagation environment and terminal speed. For well-controlled indoor wireless local-area networks, it may be relatively easy to configure reproducible QoS attributes because low terminal speeds will result in a slowly varying propagation condition due to fading. In that case, the media-access layer may be able to adaptively maintain a reasonably constant QoS over time. In contrast, in wide-area wireless networks with high terminal velocities and high carrier frequencies, fading and shadowing effects may make it extremely difficult to adaptively maintain QoS. In this case, it may be more appropriate to view the configured QoS as an objective rather than guarantee, and to assume that there is an outage probability (possibly configurable but at least provided to the application); that is, probability that the QoS objective is violated. Many intermediate situations are surely possible.
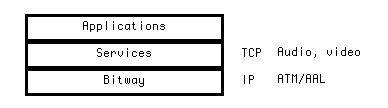
Consider two basic architectures illustrated in Figure 9 for concatenated links, where each link corresponds to one homogeneous bitway subnet. For example, in wireless access to a broadband network, the wireless subnet would constitute one bitway link, and the broadband subnet would constitute the second link. The distinction between the link architecture and the edge architecture is whether or not a services layer is included within each subnet.[8] The back-to-back services layers in the link architecture include, for CM services like audio and video, a decompression signal processing function followed by a compression function. These functions together constitute a transcoder.
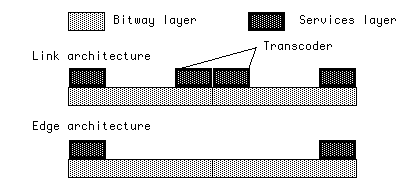
In the Internet, services layers like TCP or UDP are realized at the edges. That is, the Internet uses today the edge architecture. In extensions to the Internet architecture for realizing CM services, under some limited circumstances transcoders are proposed to be included within the network[9]; thus, the Internet is currently proposed to move (at least to a minor extent) in the direction of the link architecture.
In designing a new infrastructure, it should be possible to avoid transcoders, and we believe very desirable as well. We argue that the edge architecture is superior, and should be adopted for the future.
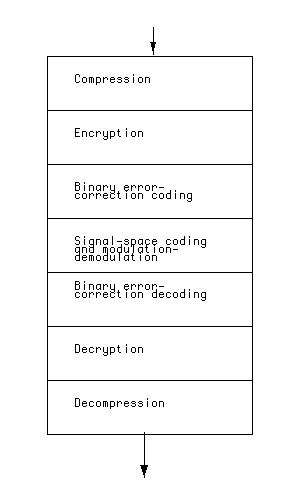
The resulting architecture is structured as in Figure 10. Compression, encryption, and QoS negotiation occur in the services layer, at the network edge. FEC, modulation, and resource reservation occur in the bitway layer, at each network link. In favor of this architecture, we mention five factors:
Encryption techniques can be divided into two classes [13]. In the binary additive stream cipher, which is used for example to encrypt the speech signal in the GSM digital cellular system [41], the data is exclusive-or'ed with the same random-looking running key generator (RKG) bit sequence at the transmitter and receiver. The RKG depends on a secret key known to both encryption and decryption [42]. The stream cipher has the advantage of no error multiplication and propagation effects; however, the loss of synchronization of the RKG will be catastrophic. A block cipher algorithm applies a functional transformation to a block of data plus a secret key to yield the encrypted block, and an inverse function at the receiver can recover the data if the key is available. For example, DES applies its transformation to blocks of 64 bits using a 56-bit key [43]. In fact, error propagation within the block is considered a desirable property of the cryptosystem; that is, block ciphers should on average modify an unpredictable half of the plaintext bits whenever a single ciphertext bit is changed (this is called the "strict avalanche property" [44]). There are variations on block ciphers with feedforward and feedback of delayed ciphertext blocks that cause error propagation beyond a single block.
Another important issue is the impact of encryption on QoS. In a general integrated services multimedia network, encryption techniques with error propagation should not be used for CM services, since this will preclude strategies designed to tolerate errors rather than mask them.
Neither a stream nor block cipher is ideal, since the stream cipher introduces serious synchronization issues in a packet network while the block cipher has severe error propagation. This is a serious issue for wireless multimedia networks that should be addressed by additional research.
In this regard, the argument in favor of the edge architecture is economic: it allows the latest technologies to be introduced into the network in an economically viable way. New signal processing technologies are initially more expensive than older technologies, since innovation and engineering costs must be recovered and they usually require more processing power. In the edge architecture, the services signal processing is realized within the user terminal or at a user access point; that is, it is provisioned specifically for the user. Only users who are willing to pay the cost penalty of the latest technology need upgrade, and only services desired for that user need be provisioned.
In contrast, in the link architecture, service signal processing elements are embedded widely throughout the network. At each point, it is necessary to deploy all services, including the latest and highest performance. The practical result is that for any users to benefit from a new technology, a global upgrade throughout the network is required. If only a relatively few users are initially willing to pay the incremental cost of new technology, there is no business case for this upgrade. There is also the question of who provisions and pays for the substantial infrastructure that would be required to support transcoding in or near basestations.
Further, the link architecture also requires that, for 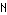 different performance flavors of a given service, internal nodes in the network be prepared to implement
different performance flavors of a given service, internal nodes in the network be prepared to implement 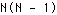 distinct transcoders, and that nodes be prepared to implement all distinct services. These nodes must also implement all feasible encryption algorithms, and must be cognizant of encryption keys. In contrast, in the edge architecture the edge nodes need only implement those services desired by the local application/user, and only the flavor with the highest desired performance (as well as fallback to lower performance flavors).
distinct transcoders, and that nodes be prepared to implement all distinct services. These nodes must also implement all feasible encryption algorithms, and must be cognizant of encryption keys. In contrast, in the edge architecture the edge nodes need only implement those services desired by the local application/user, and only the flavor with the highest desired performance (as well as fallback to lower performance flavors).
Past examples of these phenomena are easy to identify. The voiceband data modem, realized on an end-to-end basis, has advanced through two orders of magnitude in performance while simultaneously coming down in price. Users desiring state-of-the-art performance must pay a cost increment, but other users need not upgrade. If a higher performance modem encounters a less capable modem, it falls back to that mode. Realizing the older modem standards introduces only a tiny cost increment, since the design costs have been amortized and the lower performance standard requires less processing power. This example provides a useful model of how a service can be incrementally upgraded over time in the edge architecture. It illustrates that each terminal does not have to implement a full suite of standards, but rather only needs to include only those services and the highest performance desired by the local application or user, as well as fallback modes to all lower speed standards[11]. The fallback modes, which are the only concession to interoperability with other terminals, do not add appreciable cost, since the lower performance standards require less processing power, and the design costs of the older standards have been previously amortized.[12] The total end-to-end performance will be dictated by the lowest performance at the edges.
Contrast this with the circuit-switched telephone network, where the same voice coding has been entrenched since the dawn of digital transmission. This voice coding standard is heavily embedded in the network, which was originally envisioned as a voice network. Today, it would be feasible to provide a much improved voice quality (especially in terms of bandwidth) at the same bit rate, but there is no economically viable way to introduce this technology into the network.
The ability for users or third party vendors to add new or improved services, even without the involvement of the network provider, is perceived as one of the key features of the Internet, leading to the rapid deployment of new capabilities such as the World-Wide Web. In the link architecture, the necessary involvement of network service providers in services is undoubtedly a major barrier to innovation within the services domain of functionality, such as signal compression.
We can distinguish between two categories of physical layer signal processing. Transmit waveform shaping, spatial and temporal diversity combining and equalization are commonly employed wireless physical layer techniques which strive to unilaterally improve the reliability of all information bits. These methods trade off reliability for signal processing overhead (hardware cost), delay, and reduced traffic capacity. In contrast, power control and signal space codes (such as trellis-coded modulation and shell mapping) form a class of methods with an additional dimension: given a fixed amount of resources -- transmit power in the case of the former, hardware complexity and radio spectrum in the case of the latter -- these strategies can selectively allocate impairments to different information bits, thereby controlling QoS. The ability to match transmit power to loss and corruption requirements is essential for maximizing capacity in wireless cellular networks, where excessive power creates unnecessary interference to other users.
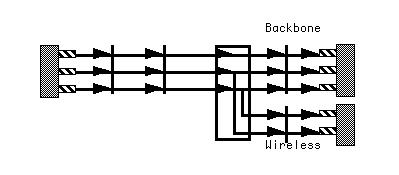
The substream abstraction (Section 3.3) enables this matching. As shown in Figure 11, each bitway link is obligated to maintain the structure of the medley gateway at its output. That is, the medley gateway is the interface between service and bitway layers, and also the interface between distinct bitway entities. This is why we call it a gateway, since it serves as a common protocol interface between heterogeneous bitway subnets. The substream structure is visible to each bitway link, which is able to allocate resources and to tailor its modulation efficiently in accordance with JSCC.
An alternative architecture is to provision reliability by applying physical layer signal processing on a link-by-link basis: each link is made cognizant of the loss and corruption requirements of an application, then applies its own specific physical layer processing to meet these requirements. This is the architecture we prefer, for reasons we will now elaborate.
The link-by-link approach to providing reliability necessitates a mechanism for QoS negotiation on each link so that it can configure itself in accordance with the requirements of a particular source stream. With binary FEC, we can do away with QoS negotiation altogether, which is certainly an advantage. However, consider the reliability requirements of the wireless link. Since the wireless link has no knowledge of the source requirements, it must be designed for a homogeneous QoS across all streams. There are two options. First, the designer can adjust the reliability for the most stringent -- or most demanding -- source. This conservative design approach will, for less stringent source requirements, over-provision resources such as bandwidth and power, and overly restrict interference, thus reducing traffic capacity. While we don't expect this to be a major issue on backbone networks, it may severely decrease the capacity of the bottleneck wireless access network if there is a wide variation in source QoS needs.
The second option is to design the wireless access link to be suitable for the least stringent source requirement, and compensate by FEC on an end-to-end basis, as in PET. This introduces several sources of inefficiency for heterogeneous networks with wireless access. As noted earlier, binary erasure codes are very efficient in combatting congestion-based losses in a wired packet network. Their performance is significantly poorer in a wireless environment, where packets are likely to be corrupted due to the inherently high bit-error rate (BER). For the 10-2 uncoded BER typical of high mobility wireless and a packet size of M = 120 bits, the packet loss rate after applying an (N=8, B=2) erasure code is:
(EQ 1) 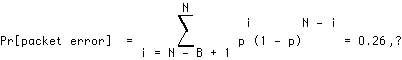
where
(EQ 2) 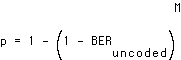 .
.
This performance is a modest improvement over the uncoded packet error rate of 70%, but was achieved by quadrupling the bandwidth. A better way of lowering losses is to attempt to reduce the corruption rate instead, for example by using a convolutional code. For the same bandwidth expansion as a (8,2) erasure code, a convolutional code can lower the BER by two orders of magnitude [38][39], thereby lowering the packet error rate to 1%. On a wireless link with rapid fading, this will usually be accompanied by interleaving to turn correlated errors into quasi-independent errors. While convolutional coding may be attractive for wireless links, it is largely ineffective in a wired network, where losses are congestion-derived. Thus, it will be necessary with end-to-end FEC to concatenate different codes and interleaving designed to combat all anticipated error mechanisms, implying that the wireless link traffic will be penalized by redundancy intended for the other links in the network as well as its own.
The link-by-link architecture also permits us to apply physical layer signal processing techniques not possible in end-to-end binary FEC. In end-to-end binary FEC, one has no choice but to perform a hard decision on the information bits as they cross from one link to another. On a wireless link, we have control over the modulation and demodulation process and thus can apply soft decoding to the information bits. Hard decisions made prior to the final decoding result in an irreversible loss of information. This loss is equivalent to a 2 dB drop in the signal-to-noise ratio [40], and the effect on loss and corruption is cumulative across multiple links. In addition, we can consider making the FEC and interleaving adaptive to the local traffic and propagation conditions on the wireless link.
Overall, active configuration of the QoS on a wireless link based on individual source requirements will substantially increase traffic capacity. The price to be paid is an infrastructure for QoS negotiation and configuration and the need to provision variable QoS in a wireless network, where the latter issue is addressed further in Section 5.1. Fully quantifying this benefit requires further research, since it depends on the characteristics and requirements of the source traffic, as well as the benefits of variable QoS.
Inherently, resources belong to individual links, not to end-to-end connections. However, the QoS negotiation between the services and bitway layers that establishes each link's resource use can be done end-to-end or link-by-link.
In the link architecture, overall subjective quality objectives must be referenced back to the individual links, since each link will contribute artifacts that impair subjective quality (such as quantization, blocking effects, error masking effects, etc.). These artifacts will accumulate across links in a very complicated and difficult-to-characterize way. (For example, how is a blocking or masking artifact represented in the next compression/decompression stage?) It is relatively straightforward to partition objective impairments like delay among the links. Other objective attributes like frame rate, bandwidth, and resolution will be dictated by the worst-case link, and are thus also straightforward to characterize. Subjective impairments due to loss and corruption artifacts will, however, be very difficult if not impossible to characterize in a heterogeneous bitway environment. Simple objective measures like mean-square error are fairly meaningless in the face of complex impairments like the masking of bitway losses. Thus, as a practical matter it will be very difficult to predict and control end-to-end subjective quality.
The situation in the edge architecture is quite different. The first step is to generate an aggregated bitway model for all the concatenated bitway links. That is, the loss models for the individual links must be referenced to a loss model for the overall connection, and similarly for corruption and delay. There are no doubt serious complications in this aggregation, like for example correlations of loss mechanisms in successive links due to common traffic. Nevertheless, this is a relatively straightforward task susceptible to analytical modeling. Once this is done, the aggregate bitway model must be related back to service subjective quality, much in the fashion of a single link in the link architecture. There is no need to characterize the accumulation of artifacts in multiple compression/decompression stages. Accurate prediction and control of subjective quality in the edge architecture should be feasible, and this is an additional advantage over the link architecture.
A variable QoS medley bitway has two design challenges: provide flexibility in loss/corruption/delay attributes with a substream granularity, and exploit the configured characteristics to maximize the traffic capacity. We will illustrate the design issues for a wireless direct-sequence code-division multiple access (CDMA) system. We will focus on achieving variable reliability, and ignore the issue of variable delay discussed elsewhere [60].
There are two handles for controlling reliability in CDMA: forward error protection (FEC) and power control. Achieving variable reliability with FEC would require unequal error protection (UEP). Many forms of UEP coding have been discovered, notably algebraic codes for UEP and embedding asymmetric constellations in trellis-coded modulation [61]. However, the number of different levels of reliability provided by these techniques is limited, and it is difficult to apply them towards hierarchical UEP. Variable rate (VR) convolutional codes have also been suggested for UEP coding of speech [62]. By adopting UEP, we can increase the reliability of a substream by adjusting the coding rate, at the expense of bandwidth expansion from the redundancy. Signal space codes such as trellis-coded modulation are particularly attractive for wireless networks as they provide redundancy without increasing bandwidth. However, it is difficult to generate (by varying the constellation size) the trellis equivalent of a variable rate convolutional code, since Ungerboeck has shown that virtually all of the coding gain is attained by doubling the alphabet size [40].
An alternative mechanism to control reliability QoS would be to adjust the signal-to-interference ratio (SINR) by adjusting the transmitted power, taking into account the interference from other user's traffic being simultaneously transmitted on different spreading codes. Of course, it is beneficial for overall traffic capacity to minimize the transmitted power for any given user in order to minimize the interference to other users. Hence, overall traffic capacity is maximized by achieving, for each packet, no greater SINR than necessary to meet the QoS objective. If we use power control only, then in a CDMA system we will be transmitting to a particular user at less than 100% duty cycle whenever the bit rate required by that user is less than the peak rate enabled by the chip rate and processing gain. Power control has some important advantages:
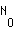 and let the bandwidth be
and let the bandwidth be 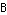 . Let
. Let 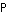 be the average transmitted power for this particular user, and transmit with a duty cycle
be the average transmitted power for this particular user, and transmit with a duty cycle 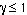 . Then, the transmitted power during that duty cycle is
. Then, the transmitted power during that duty cycle is 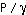 . The channel capacity using this duty cycle is
. The channel capacity using this duty cycle is 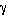 times the capacity if we transmitted at this same power level at 100% duty cycle, where the latter is
times the capacity if we transmitted at this same power level at 100% duty cycle, where the latter is 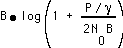 . Thus, the overall channel capacity is
. Thus, the overall channel capacity is
(EQ 3) 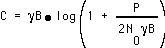 ,
,
which is precisely the same as the capacity of a channel with bandwidth 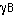 with 100% duty cycle transmission and transmitted power
with 100% duty cycle transmission and transmitted power 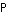 . Since this capacity is maximum for
. Since this capacity is maximum for 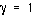 , we conclude that it is advantageous to transmit with 100% duty cycle in order to minimize the average transmitted power
, we conclude that it is advantageous to transmit with 100% duty cycle in order to minimize the average transmitted power 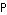 for a fixed bitrate
for a fixed bitrate 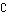 . To minimize
. To minimize 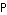 , and hence the interference to other users, we should always transmit at 100% duty cycle by adding channel coding redundancy as necessary. Intuitively, it is advantageous to use coding to increase the duty cycle of transmission to 100% regardless of the required bit rate, and take advantage of the coding gain to reduce the average transmit power.
, and hence the interference to other users, we should always transmit at 100% duty cycle by adding channel coding redundancy as necessary. Intuitively, it is advantageous to use coding to increase the duty cycle of transmission to 100% regardless of the required bit rate, and take advantage of the coding gain to reduce the average transmit power.
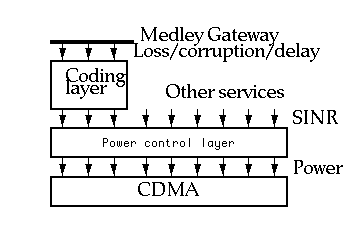
Thus, information theory teaches us that in an interference-dominated wireless channel such as CDMA, it is best to use coordinated UEP and power control. Either UEP or power control in isolation is sub-optimum at the fundamental limits. If the bitrate for a given CDMA spreading code is low, coding redundancy should be added and the transmitted power simultaneously reduced. The bitway coding and power control layers in a wireless cellular bitway design are illustrated in Figure 14. A set of substreams is applied to a coding layer which is cognizant of the propagation characteristics of the channel, and configures itself to provide the negotiated QoS contract[14]. Based on the coding selected, each substream is associated with a required signal-to-interference-noise ratio (SINR). The power control layer then associates a transmitted power with each substream, taking into account a maximum power requirement, the SINR requirement for each substream, and which substreams currently have packets awaiting transmission[15].
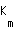 be the number of substreams of user m. Specify a user (CDMA spreading code) by subscript m and a substream by subscript k. The SINR experienced by the k-th substream of user m on the uplink is
be the number of substreams of user m. Specify a user (CDMA spreading code) by subscript m and a substream by subscript k. The SINR experienced by the k-th substream of user m on the uplink is
(EQ 4) 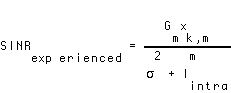 ,
,
where 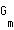 is the path loss from user m to the base station;
is the path loss from user m to the base station; 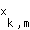 is the transmit power assigned to substream k;
is the transmit power assigned to substream k;  is the intracell interference experienced by user m, and
is the intracell interference experienced by user m, and 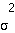 is the lump sum of background noise and intercell interference experienced at the base station.
is the lump sum of background noise and intercell interference experienced at the base station.
The intracell interference experienced by a substream of user m is
(EQ 5) 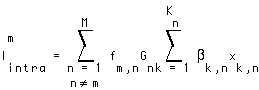 .
.
where 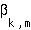 is an indicator function, equalling one if substream k of user m is currently active, zero otherwise. Each user's traffic may be decomposed into multiple substreams, but the substreams are statistically multiplexed together onto one user stream, so that only one of the user's substreams is active at any time.
is an indicator function, equalling one if substream k of user m is currently active, zero otherwise. Each user's traffic may be decomposed into multiple substreams, but the substreams are statistically multiplexed together onto one user stream, so that only one of the user's substreams is active at any time. 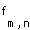 is the partial correlation coefficient (or degree of non-orthogonality) between channels of users m and n: because signals from different mobile users travel through different multipath channels to reach the base station, perfect orthogonality between user codes may be lost and
is the partial correlation coefficient (or degree of non-orthogonality) between channels of users m and n: because signals from different mobile users travel through different multipath channels to reach the base station, perfect orthogonality between user codes may be lost and 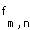 may be non-zero. Uplink transmission is inherently asynchronous, so
may be non-zero. Uplink transmission is inherently asynchronous, so 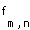 is well modeled by f, the correlation between random signature sequences, with
is well modeled by f, the correlation between random signature sequences, with 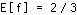 [65].
[65].
The indicator function of a substream as it evolves over time, 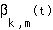 ,
, 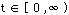 , is a random process. Let
, is a random process. Let 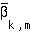 denote the long-term time-average of
denote the long-term time-average of 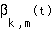 ; e.g.
; e.g. 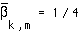 if the average bitrate of substream k is 500 kbps and it belongs to a 2 Mbps user stream. We assume ergodicity in the mean, so that
if the average bitrate of substream k is 500 kbps and it belongs to a 2 Mbps user stream. We assume ergodicity in the mean, so that 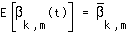 . This is based on the intuition that at any given time slot, the probability that you receive a packet from substream k equals the average rate of that substream, divided by the aggregate rate of the user stream to which it belongs. The expected value of the total power is then
. This is based on the intuition that at any given time slot, the probability that you receive a packet from substream k equals the average rate of that substream, divided by the aggregate rate of the user stream to which it belongs. The expected value of the total power is then
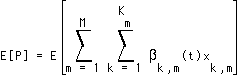
(EQ 6) 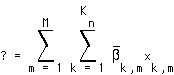 .
.
Our objective is to minimize the average overall power 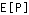 , while promising each substream that the expected value of the SINR it experiences will meet or exceed the desired SINR:
, while promising each substream that the expected value of the SINR it experiences will meet or exceed the desired SINR:
(EQ 7) minimize 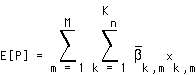 such that
such that
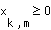 ,
, 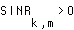
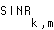 is the signal-to-interference-noise ratio requested by substream k of user m, and the inequality in Eq. 8 implies that the expected value of the SINR achieved at the receiver must equal or exceed the desired SINR.
is the signal-to-interference-noise ratio requested by substream k of user m, and the inequality in Eq. 8 implies that the expected value of the SINR achieved at the receiver must equal or exceed the desired SINR.
It can be shown [66] that the feasible capacity region of a CDMA system is given by
(EQ 10) 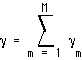 ,
,
(EQ 11) 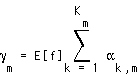 , and
, and
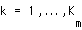 ,
, 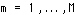 .
.
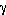 , the left hand side of Eq. 9, represents the load of the system. The closer
, the left hand side of Eq. 9, represents the load of the system. The closer 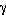 is to unity, the closer the system is to violating the QoS requirements for all users and substreams. If the QoS requirements are too stringent, then the interference will be too great and no solution exists, regardless of the transmit power. Examining Eq. 12, we see that for a cellular wireless system whose capacity is interference-limited, the "cost" of transmitting an information substream is the product of its reliability requirement (specified by an SINR) and bandwidth requirement (specified by its average rate
is to unity, the closer the system is to violating the QoS requirements for all users and substreams. If the QoS requirements are too stringent, then the interference will be too great and no solution exists, regardless of the transmit power. Examining Eq. 12, we see that for a cellular wireless system whose capacity is interference-limited, the "cost" of transmitting an information substream is the product of its reliability requirement (specified by an SINR) and bandwidth requirement (specified by its average rate 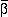 ).
).
As noted earlier, information theory suggests that the application of VR coding to adapt a variable-rate information source to a bandlimited channel is necessary in order to maximize capacity. In a CDMA system, a user is associated with a code, and the bandwidth afforded by the code is shared by the user's substreams. Each substream is allocated a time-averaged fraction of the bandwidth, 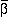 . To ensure optimal capacity in the information theoretic system, the bandwidth associated with the code should be used at 100% duty cycle; i.e., in Eq. 9 - Eq. 12,
. To ensure optimal capacity in the information theoretic system, the bandwidth associated with the code should be used at 100% duty cycle; i.e., in Eq. 9 - Eq. 12, 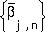 satisfy
satisfy
(EQ 13) 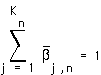
 ,
,
with the SINR requirements of all substreams adjusted for the resulting coding gain. We note that the interference-limited capacity result as stated in Eq. 9 - Eq. 12 is quite general, and can also be applied towards suboptimal systems which do not achieve 100% utilization of the channel bandwidth.
We can apply these results to find the capacity gain of power control for variable QoS with substreams over power control without substreams. In the absence of substreams, each stream's reliability requirement would be equal to the reliability need of its worst case (most error-sensitive) information component. A fine-grained substream architecture therefore achieves a capacity gain of
where 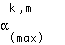 corresponds to the maximum SINR requirement among the substreams of stream k.
corresponds to the maximum SINR requirement among the substreams of stream k.
MPEG-2 is a service layer standards, and today is used with a range of bitways: direct broadcast satellite, digital switched line, cable television, ATM, and more. As a suite of service layer standards, MPEG-2 does not provide bitway QoS-enhancing functionality such as data interleaving, selective packet discard, or FEC. Still, MPEG-2 does provide a range of functionality to help resynchronize and recover quickly from bitway errors and to configure to trade off efficiently between bandwidth, delay, loss, and service quality.
The audio and video compression methods defined by MPEG-2 contain many predictive coding steps. For example, the video specification includes interframe motion-compensated DPCM, predictive coding of motion vectors within a frame, predictive coding of DCT brightness coefficients within a frame, etc. Predictive coding, which represents a signal's difference from a predicted value rather than representing the signal value directly, removes signal redundancy very effectively but suffers from error propagation. Errors cause predictive decoders to incorrectly render data which is used in future predictions. These subsequent predictions with errors lead to more incorrectly decoded data; this propagates errors throughout spatiotemporally nearby audio or video. Fortunately, MPEG-2 allows an encoder to define "resynchronization points" almost as often or infrequently as the designer desires, to trade between bandwidth efficiency and rapid error recovery. At a "resynchronization point," signal values are coded directly rather than via a predictor.
Both the audio and video compression algorithms use Huffman coding, which uses short bitstrings to represent frequently occurring values and long bitstrings to represent infrequent values. A property of Huffman codes is that they cannot be decoded without some context--knowledge of the bit position of the start of some bitstring. Huffman codes also suffer error propagation: one bit error destroys the decoder's context, and the decoder may incorrectly decode a long sequence of values. To alleviate this problem, the audio and video specifications both define "startcodes," which are patterns in the bitstreams that decoders can find easily and at which Huffman codes are known to be at the start of a bitstring. These startcodes do consume a small but nonzero percentage of audio and video stream bandwidth, but they enable decoder recovery after a transmission error. The video specification allows bitstream encoders to insert "slice" startcodes at either a default minimum rate or at a higher rate to enable faster-than-default error recovery.
The systems specification defines a bitstream format ("transport streams") that consists of short (compared to TCP/IP) fixed-length packets. Short packets ensure that if a receiver identifies a packet as corrupted, comparatively little data is suspect. Fixed-length packets facilitate rapid identification of packet delineators after errors.
MPEG-2 transport streams can contain "duplicate packets." A duplicate packet is a copy of the previous packet with the same source identifier. Duplication is a simple (but not efficient) flavor of FEC. Combined with bitway interleaving, duplication greatly reduces the occurrence of uncorrectable burst errors, however. A sensible strategy is to duplicate all packets that contain the highest-level startcodes.
EXAMPLE:
The MPEG-2 systems specification defines a timing recovery and synchronization method that utilizes two types of timestamps. "Program clock references" allow receivers to implement accurate phase-locked loop clock recovery. Stringent limitations on the encoder clock frequency accuracy and drift rate allow decoders to identify and discard corrupted PCR's. Video frames and audio segments are identified by Decode/Presentation Timestamps, which tell the decoder the proper time to decode and present the associated video and audio data. Since each frame has a fixed (and known to the decoder) duration, there is a lot of redundancy in the DTS/PTS values. However, the small amount of bandwidth spent on PCR's and DTS/PTS's helps decoders properly prefill their input buffers and properly synchronize their video and audio outputs after errors.
The MPEG-2 systems, video, and audio subparts only specify bitstream formats. Another part of MPEG-2, the Real-Time Interface (RTI), defines constraints on real-time delivery of systems bitstreams to actual decoders. The RTI defines a method for measuring the delay jitter present when a bitstream is delivered to a decoder; this aids in ensuring interoperability between bitstream providers and decoders. The RTI does not mandate a specific delay jitter value; the designer chooses a value suitable for his/her system, e.g. 50 microseconds for a low-jitter connection between a digital VCR and a decoder, or more than 1 millisecond for an international ATM connection. The RTI defines decoder memory requirements and bitstream delivery constraints based on the chosen jitter value. The specification of decoder memory requirements as a function of delay jitter is very important for many MPEG-2 applications, where decoder cost, largely driven by memory, is the biggest determinant of commercial viability.
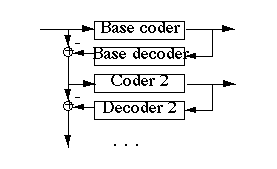
A simple example of a hierarchical video coder simply transmits a picture's pixels' most significant bits on one substream and least significant bits on another. If some of the least significant bits are lost, affected picture regions appear coarsely quantized but certainly recognizable.
The MPEG-2 video specification defines several much more sophisticated ways by which an encoder can produce a two- or three-layer hierarchically encoded bitstream. MPEG-2 video allows an encoder to generate hierarchical bitstreams that decompose a signal into low frame-rate vs. high frame-rate components, small picture size vs. large picture size, or low image fidelity vs. high image fidelity (called "SNR scalability") components. Several of these decompositions can be used in tandem as well.
MPEG-2 video defines another scalability tool called "data partitioning." Data partitioning defines how to split a non-hierarchically-encoded bitstream into two substreams. The "high priority" substream contains video headers and other "important" syntax elements such as motion vectors. The "low priority" bitstream contains "lower priority" syntax elements such as high-frequency DCT coefficients. The encoder can choose its definition of "high priority" and "low priority" syntax elements to achieve its best trade-off between high-priority bandwidth, high-priority QoS, low-priority bandwidth, and low-priority QoS.
Since substreams have different delay characteristics, it is inherent that they are asynchronous at the receiving terminal. They can be resynchronized by an appropriate medley transport protocol, but not resynchronizing them allows the delay characteristics of the bitway to be exploited. To this end, the medley gateway abstractions offer several key benefits;
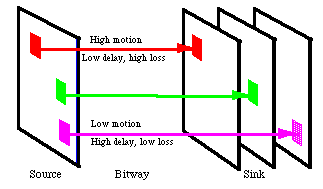
An early example of delay-cognizant video coding is asynchronous video [68], a coding technique that exploits variations in the temporal dimension of video to segment information into distinct delay classes. While we leave the details to other references [68], the basic idea is illustrated in Figure 16. The frame is block segmented into different delay and reliability classes in accordance with motion estimation (three classes are shown). These different classes are allowed to be offset at the receiver by one or more frames in the reconstruction process. The hope is that low-motion blocks are less susceptible to multiple-frame delay jitter at the receiver than are high-motion blocks, and that the user perception of delay will be dominated by the high-motion blocks. If this is the case, low-motion blocks can be assigned to a medley bitway substream with a relaxed delay objective, and the bitway can exploit this relaxed delay jitter objective to achieve higher traffic capacity. In addition, high motion blocks are assigned to substreams with a relaxed reliability objective, since the motion tends to subjectively mask losses or corruption. Fortuitously, the bitway naturally provides precisely the needed exchange of higher reliability for higher delay.
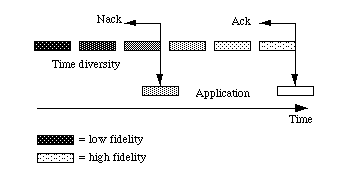
The considerations covered in this chapter suggest many opportunities for research, which include:
2. L. Zhang, S. Deering, D. Estrin, S. Shenker, D. Zappala, '"RSVP: a new resource reservation protocol," IEEE Network, Sept. 1993, p. 8.
3. National Research Council, Computer Science and Telecommunications Board, Realizing the Information Future; The Internet and Beyond. Washington, DC: National Academies Press, 1994.
4. D.G. Messerschmitt, "Complexity management: A major issue for telecommunications," International Conference on Communications, Computing, Control, and Signal Processing in Honor of Prof. Thomas Kailath, A.Paulraj, V. Roychowdhury, C. Schaper, editors, Boston: Kluwer Academic Press, 1996.
5. "Intelligent Networks," IEEE Communications Magazine, Feb 1992, vol. 30:2.
6. M. Lengdell, J. Pavon, M. Wakano, M. Chapman, and others, "The TINA network resource model," IEEE Communications Magazine, March 1996, vol. 34:3, pp. 74-79.
7. F. Dupuy, C. Nilsson, Y. Inoue, "The TINA consortium: toward networking telecommunications information services," IEEE Communications Magazine, Nov. 1995, vol. 33:11, pp. 78-83.
8. D.G. Messerschmitt, "The future of computer-telecommunications integration," invited paper in IEEE Communications Magazine, special issue on "Computer-Telephony Integration," April 1996.
9. D.G. Messerschmitt, "The convergence of communications and computing: What are the implications today?," IEEE Proceedings, August 1996.
10. D.G. Messerschmitt, "Convergence of telecommunications with computing," invited paper in special issue on "Impact of Information Technology," Technology in Society, Elsevier Science Ltd., to appear.
11. A.G. MacInnis, "The MPEG systems coding specification," Signal Processing: Image Communication, April 1992, vol. 4:2, pp. 153-159.
12. C. Holborow, "MPEG-2 Systems: a standard packet multiplex format for cable digital services," Proc. 1994 Conference on Emerging Technologies, Society of Cable Television Engineers, Phoenix, AZ., Jan. 1994.
13. J. Massey, "An introduction to contemporary cryptology," Proceedings of the IEEE, Special Section on Cryptology, May 1988, p. 533.
14. D.J. Le Gall, "The MPEG video compression algorithm," Signal Processing: Image Communication, April 1992, vol. 4:2, pp. 129-140.
15. D.J. Le Gall, "MPEG: a video compression standard for multimedia applications," Communications of the ACM, April 1991, vol. 34:4, pp. 46-58.
16. ISO/IEC standard 11172, "Coding of Moving Pictures and Associated Audio at up to about 1.5 Mbits/s." (MPEG-1).
17. ISO/IEC standard 13818, "Generic Coding of Moving Pictures and Associated Audio." (MPEG-2).
18. J.E. Natvig, S. Hansen, J. de Brito, "Speech processing in the pan-European digital mobile radio system," Proc. GLOBECOM, Dallas, TX, 27-30 Nov. 1989.
19. T.H. Meng, B.M. Gordon, E.K. Tsern, A.C. Hung, "Portable video-on-demand in wireless communication," Proceedings of the IEEE, April 1995, vol. 83:4, pp. 659-680.
20. D. Ferrari, "Real-time communication in an internetwork," Journal of High Speed Networks, 1992, vol. 1:1, pp. 79-103.
21. D. Ferrari, "Delay jitter control scheme for packet-switching internetworks," Computer Communications, July-Aug. 1992, vol. 15:6, pp. 367-373.
22. S. Vembu, S. Verdu, Y. Steinberg, "The source-channel separation theorem revisited," IEEE Transactions Information Theory, Jan. 1995, vol. IT-41:1.
23. A. Goldsmith, "Joint source/channel coding for wireless channels," 1995 IEEE 45th Vehicular Technology Conference. Countdown to the Wireless Twenty-First Century, Chicago, IL, 25-28 July 1995.
24. S. McCanne, M. Vetterli, "Joint source/channel coding for multicast packet video," Proceedings International Conference on Image Processing, Washington, DC, 23-26 Oct. 1995.
25. M. Khansari, M. Vetterli, "Layered transmission of signals over power-constrained wireless channels," Proceedings International Conference on Image Processing, Washington, DC, 23-26 Oct. 1995.
26. M.W. Garrett, M. Vetterli, "Joint source/channel coding of statistically multiplexed real-time services on packet networks," IEEE/ACM Transactions on Networking, Feb. 1993, vol. 1:1, pp. 71-80.
27. K. Ramchandran, A. Ortega, K.M. Uz, M. Vetterli, "Multiresolution broadcast for digital HDTV using joint source/channel coding," IEEE Journal on Selected Areas in Communications, Jan. 1993, vol. 11:1, pp. 6-23.
28. L. Yun, D.G. Messerschmitt, "Power Control and Coding for Variable QOS on a CDMA Channel," Proc. IEEE Military Communications Conference, Oct. 1994.
29. N. Chaddha, T.H. Meng, "A low-power video decoder with power, memory, bandwidth and quality scalability," VLSI Signal Processing, VIII, Sakai, Japan, 16-18 Sept. 1995.
30. T.H. Meng, E.K. Tsern, A.C. Hung, S.S. Hemami, and others, "Video compression for wireless communications," Virginia Tech's Third Symposium on Wireless Personal Communications Proceedings, Blacksburg, VA, 9-11 June 1993.
31. R. Han, L.C. Yun, and D.G. Messerschmitt, "Digital Video in a Fading Interference Wireless Environment," IEEE Int. Conf on Acoustics, Speech, and Signal Processing, Atlanta, GA, May 1996.
32. J.M. Reason, L.C. Yun, A.Y Lao, D.G. Messerschmitt, "Asynchronous Video: Coordinated Video Coding and Transport for Heterogeneous Networks with Wireless Access," Mobile Computing, H.F. Korth and T. Imielinski, editors, Boston: Kluwer Academic Press, 1995.
33. D. Anastassiou, "Digital television," Proceedings of the IEEE, April 1994, vol. 82:4, pp. 510-519.
34. S.-M. Lei, "Forward Error Correction Codes for MPEG2 over ATM," IEEE Transactions on Circuits and Systems for Video Technology, April 1994.
35. L. Montreuil, "Performance of coded QPSK modulation for the delivery of MPEG-2 stream compared to analog FM modulation," Proc. National Telesystems Conference, 1993.
36. R.J. Siracusa, K. Joseph, J. Zdepski, D. Raychaudhuri, "Flexible and robust packet transport for digital HDTV," IEEE Journal on Selected Areas in Communications, Jan. 1993, vol. 11:1, pp. 88-98.
37. A. Albanese, J. Blomer, J. Edmonds and M. Luby. "Priority encoding transmission," International Computer Science Institute Technical Report TR-94-039, Berkeley, CA, Aug. 1994.
38. J. Hagenauer, N. Seshadri and C.E. Sundberg, "The performance of rate-compatible punctured convolutional codes for digital mobile radio," IEEE T. on Communications, July 1990, vol. 38:7, pp. 966-980.
39. J. Proakis, Digital Communications, 2nd edition., McGraw Hill, 1989.
40. G. Ungerboeck, "Channel coding with multilevel/phase signals," IEEE T. on Information Theory, Jan. 1982, vol. IT-28:1, pp. 55-67.
41. E. Zuk, "GSM security features," Telecommunication Journal of Australia, 1993, vol. 43:2, pp. 26-31.
42. D. Gollmann, DW.G. Chambers, "Clock-controlled shift registers: a review," IEEE Journal on Selected Areas in Communications, May 1989, vol. 7:4, pp. 525-533.
43. M. Smit, and D. Branstad, "The Data Encryption Standard: past and future," Proceedings of the IEEE, Special Section on Cryptology, May 1988, p. 550.
44. A. F. Webster and S. E. Tavares, "On the design of S-boxes," in Advances in Cryptology - Proc. of CRYPTO '85, H. C. Williams, editor, NY: Springer-Verlag, 1986, pp. 523-534.
45. P. Haskell, "Flexibility in the Interaction Between High-Speed Networks and Communication Applications," Electronics Research Laboratory Memorandum UCB/ERL M93/83, University of California at Berkeley, Dec. 2, 1993.
46. E.A. Lee and D.G. Messerschmitt, Digital Communication, Second Edition, Boston: Kluwer Academic Press, 1993.
47. C. Topolcic, "Experimental Internet Stream Protocol, Version 2 (ST-II)," Internet RFC 1190, October 1990.
48. C. Bradner and A. Mankin, "The Recommendation for the IP Next Generation Protocol," Internet Draft, NRL, October 1994.
49. P. Pancha and M. El Zarki, "MPEG coding for variable bit rate video transmission," IEEE Communications Magazine, May 1994, vol. 32:5, pp. 54-66.
50. P. Pancha and M. El Zarki, "Prioritized transmission of variable bit rate MPEG video," Proc. GLOBECOM'92.
51. Q.-F. Zhu, Y. Wang, L. Shaw, "Coding and cell-loss recovery in DCT-based packet video"."IEEE Transactions on Circuits and Systems for Video Technology, June 1993, vol. 3:3, pp. 248-258.
52. H. Eriksson, "MBone: the Multicast Backbone," Communications of the ACM, Aug. 1994, vol. 37:8, pp. 54-60.
53. "RTP: A transport protocol for real-time applications", Internet Engineering Task Force Draft Document, July 18, 1994.
54. B. Schneier, Applied Cryptography, Protocols, Algorithms, and Source Code in C. New York: John Wiley & Sons, 1994.
55. H.R. Liu, "A layered architecture for a programmable data network," Proc. Symposium on Communications Architectures & Protocols, Austin, TX, 8-9 March 1983.
56. D.A. Keller and F.P. Young, "DIMENSION AIS/System 85-the next generation meeting business communications needs," Proc. IEEE International Conference on Communications, Boston, MA, 19-22 June 1983.
57. H.O. Burton and T.G. Lewis, "DIMENSION AIS/System 85 system architecture and design," Proc. IEEE International Conference on Communications, Boston, MA, 19-22 June 1983.
58. J.M. Cortese, "Advanced Information Systems/NET 1000 service," Proc. IEEE International Conference on Communications, Boston, MA, 19-22 June 1983.
59. S.A. Abraham, H.A. Bodner, C.G. Harrington, R.C. White, Jr., "Advanced Information Systems (AIS)/Net 1000 service: technical overview," Proc. IEEE INFOCOM, San Diego, CA, 18-21 April 1983.
60. L.C. Yun, Transport of Multimedia on Wireless Networks, Ph.D. dissertation, University of California at Berkeley, 1995.
61. L.-F. Wei, "Coded modulation with unequal error protection," IEEE Trans. Communications, Oct. 1993, vol. 41:10, pp. 1439-1449.
62. R.V. Cox, J. Hagenauer, N. Seshadri and C.-E.W.Sundberg, "Subband speech coding and matched convolutional channel coding for mobile radio channels," IEEE Trans. Signal Processing, Aug. 1991, vol. 39:8, pp. 1717-1731.
63. A.J. Viterbi, "Very low rate convolutional codes for maximum theoretical performance of spread-spectrum multiple-access channels," IEEE J. Selected Areas in Communications, May 1990, vol. 8:4.
64. D. Divsalar and M.K. Simon, "The design of trellis coded MPSK for fading channels: performance criteria," IEEE T. on Communications, Sept. 1988, vol. 36:9, pp. 1004-1012.
65. M.B. Pursley, "Performance evaluation for phase coded spread-spectrum multiple access communication - Part I: System Analysis," IEEE Trans. Communications, August 1977, vol. COM-25, pp. 795-799.
66. L.C. Yun and D.G. Messerschmitt, "Variable quality of service in CDMA systems by statistical power control," IEEE International Conf on Communications, Seattle, WA, June 18-21, 1995.
67. ISO/IEC standard 14496, "Coding of Audio-Visual Objects." (MPEG-4).
68. A. Lao, J. Reason, and D.G. Messerschmitt, "Layered asynchronous video for wireless services," IEEE Workshop on Mobile Computing Systems and Applications, Santa Cruz, CA., Dec. 1994.
69. M. Kawashima, C.-T. Chen, F.-C. Jen, S. Singhal, "Adaptation of the MPEG video-coding algorithm to network applications," IEEE Transactions on Circuits and Systems for Video Technology, Aug. 1993, vol. 3:4, pp. 261-269.
70. R. Han and D.G. Messerschmitt, "Asymptotically Reliable Transport of Text/Graphics Over Wireless Channels," Proc. Multimedia Computing and Networking, San Jose, CA, January 29-31 1996.
71. R. Han and D.G. Messerschmitt, "Asymptotically Reliable Transport of Text/Graphics over Wireless Channels," ACM/Springer Verlag Multimedia Systems Journal, to appear 1997.
72. S. Sheng, and others, "A portable multimedia terminal," IEEE Communications Magazine, Dec. 1992, vol. 30:12, pp. 64-75.
David Messerschmitt is with the University of California at Berkeley. Paul Haskell and Louis Yun were with the University of California at Berkeley. Paul Haskell is now with General Instrument Corporation and Louis Yun is now with ArrayComm, Inc. This research is supported by Bell Communications Research, Pacific Bell, Tektronix, MICRO, and the Defense Advanced Research Projects Agency.
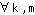 ,
, 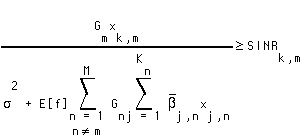 ,
,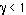 , where
, where