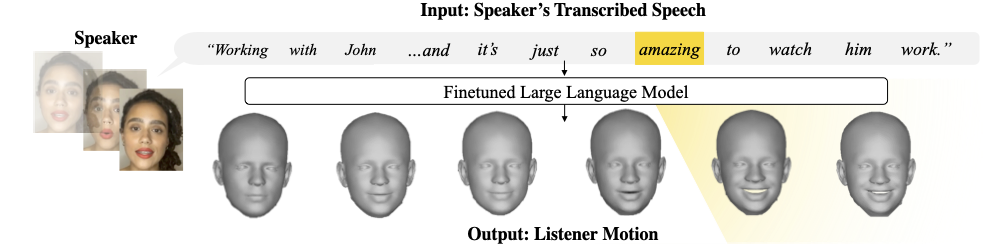
Language models transfer to listener motion prediction. Given a video of a listener and speaker pair, we extract text
corresponding to the spoken words of the speaker. We fine-tune a pretrained large language model to autoregressively generate realistic 3D
listener motion in response to the input transcript. Our method generates semantically meaningful gestures (e.g. an appropriately timed
smile inferred from “amazing”) that synchronously flow with the conversation. We can optionally render the output of our approach as
photorealistic video. Please see supplementary video
for results.
Abstract
We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words.
Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener:
a sequence of listener facial gestures, quantized using a VQ-VAE.
Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a
transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results
in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is
fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the
model's ability to utilize temporal and semantic aspects of spoken text.
Overview
Given text transcript of speech, our model generates synchronous, semantically meaningful listener reactions.
Our key contribution is in demonstrating that gestures can be discretized into atomic elements and treated as novel language tokens.
Analysis
(1) Our central insight is to transfer knowledge from pretrained large language models to the gesture generation task.
We fine-tune an LLM to ingest and output discrete atomic motion elements represented as novel language tokens.
Our causal model can produce real-time listener responses by taking time-aligned text tokens as input.
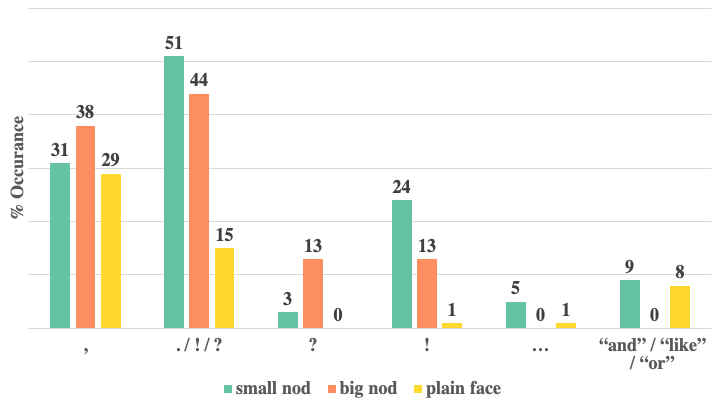
(2) Surprisingly, text transcripts of speakers’ speech contain temporal signals correlating with listeners’ nodding, beat-like responses.
The fine-tuned LLM learns these correlations.
When Analyzing the dataset, we found that most statements immediately
preceding a nod include some form of punctuation (,/.,!).
Furthermore, certain expressions correlate more strongly with certain punctuations,
allowing us to model temporally-relevant motion reactions through text tokens.
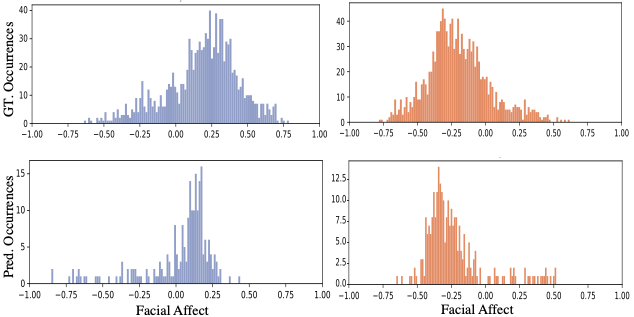
(3) The fine-tuned LLM captures semantic correlations between the text transcription of the speaker’s speech and the listener’s expression.
Given the top 100 most positive (left) and negative (right) phrases, we plot a histogram of a listener’s facial affect during
and 2 seconds after the stated phrase. -1 corresponds to very upset. The ground truth distribution (top) and our predicted distribution
(bottom) exhibit a robust correlation
(4) Given that listening is inherently multimodal, failures occur when video or auditory input from the speaker is critical.
Our method generates synchronous, semantically meaningful listeners given a speaker’s text transcript.
Fun Results
Since our model takes as input text only, we can use an outside text prompter to generate reactions.
Paper
BibTex
@inproceedings{ng2023text2listen,
title={Can Language Models Learn to Listen?},
author={Ng, Evonne and Subramanian, Sanjay
and Klein, Dan and Kanazawa, Angjoo
and Darrell, Trevor and Ginosar, Shiry},
booktitle={Proceedings of the International
Conference on Computer Vision (ICCV)},
year={2023}
}
Acknowledgements
The work of Ng, Subramanian and Darrell is supported by BAIR’s industrial alliance programs, and the DoD DARPA’s Machine Common Sense and/or SemaFor programs.
Ginosar’s work is funded by NSF under Grant #2030859 to the Computing Research Association for CIFellows Project