A parallel program written using message passing consists of a (possibly different) sequential program running on each processor, written in a conventional sequential language like Fortran or C or C++, with subroutine calls to a communication library, which communicate or synchronize with other processors. Typically there is a single program text (a single .c file, say) executed by each processor, which can branch depending on the local processor number, and so perform different tasks on each processor. Having just one program text (which makes programming much easier) is called SPMD, or single-program-multiple-data programming style.
The communication library we will use for our Sharks and Fish examples is CMMD, which runs only on the CM-5, and so is not portable. But all communication libraries provide broadly similar facilities, so little generality will be lost. Portable libraries include PVM (Parallel Virtual Machine) and MPI (Message Passing Interface). You can get PVM free of charge and install it on any network of workstations. You can also install it on a single workstation, with different UNIX processes playing the role of different processors, thereby letting you debug your code on a single machine; this is attractive facility. MPI is a standard agreed upon by numerous manufacturers, and provides much faster communication than PVM, which relies on the operating system to perform communication, which adds a great deal of overhead.
In the future, we will add PVM and MPI implementations of Sharks_and_Fish to our collection, and update this chapter to use MPI instead of CMMD.
Message passing is particularly suited to distributed memory machines, where each processor can directly access only data in its local memory. It assumes the least support from the architecture, in the sense that all the details can be hidden within the communication library. This means that message passing is simultaneously the most portable form of parallel programming (if one uses PVM or MPI), but also the most tedious and error prone, because most details of data layout and scheduling communications is left to the user. Indeed, it is tempting to call message passing the assembly language of parallel computing.
We begin our study of message passing by examining the CMMD solution of the first Sharks and Fish problem, fish swimming in a current. The solutions are written in C with calls to CMMD. They could also have been written in Fortran with no change in the use of CMMD. There are actually two source files to examine, which you should pop up in separate windows: the control processor code, called fish.cp.c, and the processor node code, called fish.pn.c. The control processor code runs on the "front end" of the CM-5 (the Sparc you login to, rodin), and the processor node code runs in parallel on all the processors. (It is also possible to write message passing code without a distinguished control processorr; one of the other processors can play the same role.)
The host proceeds to read input arguments, and computes
myfish = fish/CMMD_partition_size(),
the number of fish each node will own, which is equal
to the total number of fish divided by the number of processors.
Then the host broadcasts the input data to all the processors by calling
CMMD_bc_from_host(&host_data, sizeof(host_data)).
The nodes receive this broadcast data by calling
CMMD_receive_bc_from_host(&node_data, sizeof(node_data)).
These calls are also synchronous: only after all nodes and the host call their
respective routines and the broadcast is completed, do all subroutines
simultaneously return. If one node failed to call CMMD_receive_bc_from_host,
the other processors would hang. Also, all the processors should agree on the
number of bytes being sent, namely sizeof(node_data). So in contrast to CM Fortran,
where all the details of comunication were handled implicitly by the compiler,
with message passing the user must handle these details explicitly.
At this point the nodes compute myfish, the number of fish they will each simulate (by the same formula as above). Then they malloc the space needed to store the fish, and initialize them to some reasonable values. Each processor initializes its fish somewhat differently by having it depend on MYPROC = CMMD_self_address(), the number of each processor, which runs from 0 to CMMD_partition_size()-1.
Now the nodes start looping over the time steps of the simulation, updating their local fish positions and velocities. This is straightforward sequential C code. Periodically, every steps_per_display time steps, the nodes send their local fish positions back to the host for graphical display. To do this, each node calls
CMMD_send(CMMD_host_node(), ! number of destination (receiving) processor
0, ! message tag
Fish ! pointer to start of data to be sent
sizeof(fish_t)*myfish) ! number of bytes to send
to send a message to the host containing the local fish data. The second
argument, the message tag, is used to label messages,
and is a kind of "return address" that can be used by the receiving processor
to sort its incoming mail. The host in turn must receive a message from each
processor by calling
CMMD_receive (j, ! number of source (sending) processor
0, ! message tag
&allfish[j*myfish], ! pointer to location to store incoming data
sizeof(fish_t)*myfish) ! number of bytes to send
in a loop from j=0 to CMMD_partition_size()-1. To receive a message,
not only must the destination node specified in CMMD_send() and
the source node specified in CMMD_receive() match, but the
tags must match. One can also specify the source node
as CMMD_ANY_NODE to match any sending node, and specify the
tag as CMMD_ANY_TAG to match any incoming tag.
The size of the incoming message must be at least as big as the
size of the message sent. (One can query how many bytes actually arrived,
by calling yet another CMMD library routine.)
These sends and receives are also called synchronous, or blocking. (Later releases of CMMD use CMMD_send_block instead of CMMD_send, and CMMD_receive_block instead of CMMD_receive, to distinguish from other kinds of send and receive we will discuss shortly.) This means that the sending node does not continue executing until the receive has been executed and the transmission completed. Similarly, the receive does not return until the transmission is completed. In other words, blocking sends and receives must come in matching pairs, or else the program will hang.
Now we discuss the computation of the root-mean-square fish velocity, which requires computing a global sum of local sum-of-squared-velocities. The local sums computed on each processor are called vsum. The global sum is computed by having each node call
vsum = CMMD_reduce_to_host_float(vsum, CMMD_combiner_fadd);
and the host call
vsum = CMMD_reduce_from_nodes_float (0, CMMD_combiner_fadd);
These synchronous calls compute the global floating point sum
(as indicated by the second argument CMMD_combiner_fadd) of the
first argument (vsum), returning the same result everywhere.
The global maximum of the velocities (maxv) and accelerations (maxa)
are computed similarly. The time step dt=MIN(0.1*maxv/maxa,1) is
computed redundantly on each processor, rather than having
one processor compute it and broadcast it. This is because the
redundant computation is much less expensive than the broadcast.
The final operation is a global maximum of
the local CPU times to get the overall running time.
We wish to illustrate one other CMMD routine, which is used in the solution of the second Sharks and Fish problem: fish with gravity. As before, there are actually two source files to examine, which you should pop up in separate windows: the control processor code, called fish.cp.c, and the processor node code, called fish.pn.c. Recall that in our current solution, each fish position must be combined with every other fish position in order to compute the gravitational force. The approach taken in fish.pn.c is to have each node call
CMMD_concat_with_nodes(Fish,AllFish,sizeof(AFish)*myfish);
in order to make a copy of all fish data on all processors.
Here Fish is the local fish array, AllFish is another array large enough
to contain all fish data, and the last argument is the size of the
local fish data. This synchronous subroutine returns with a copy of each
local Fish occupying part of AllFish. This is not intended to
be an efficient solution, especially in memory: there needs
to be a completely redundant copy of all the data on each processor.
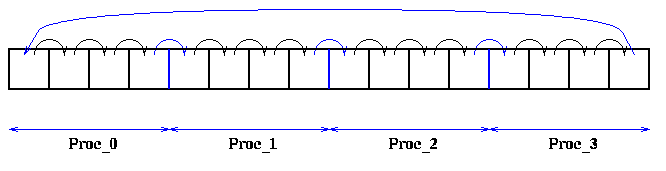
First, as in the CM Fortran and Matlab solutions, we can make a second copy of the data, called FISHp, and rotate it among the processors. In other words, we could compute the contribution to each local fish force from one other fish, and then rotate the second copy FISHp by one fish, repeating the process until all fish had contributed to all fish forces. Most rotating fish in FISHp would remain on the same processor, with those at the "boundary" requiring communication, as shown below in blue, where 16 fish are spread over 4 processors:
Alternatively, we could loop over all the local fish, computing all myfish^2 local force contributions of FISHp to FISH, and then rotate by myfish, getting an entirely new subset of FISHp.
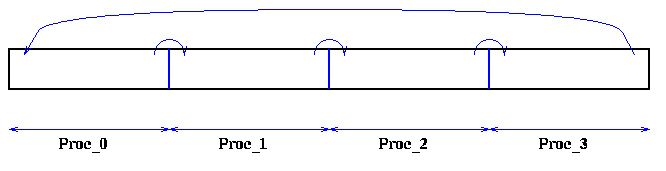
The first solution does number_of_fish rotations (communications) of one fish each. The second solution does p-1 rotations of myfish = number_of_fish / p fish each. Which is faster?
To predict which is faster requires a performance model for communication. The simplest model we will use for communication is the following one: The time it takes to send n bytes from one processor to one other processor is
alpha + beta n
where alpha is the latency (in units of seconds) and beta is the
inverse of bandwidth, where bandwidth is in units of bytes/second.
We will supply numbers for these later, but on the CM-5, you can
expect a bandwidth of about 5 Megabytes/second, or beta = .2 microseconds/byte.
Alpha is much larger, tens or hundreds of microseconds. Thus,
the first solution, which sends number_of_fish-1 messages each of size 1,
costs
(number_of_fish-1)*alpha + (number_of_fish-1)*beta seconds.The second solution, which sends p-1 messages each of size myfish = number_of_fish/p, costs
(p-1)*alpha + (p-1)*myfish*beta =
(p-1)*alpha + number_of_fish*(p-1)/p*beta seconds.
Comparing the two timings, the coefficients of beta are nearly the same:
all the fish still have to visit all the processors. But the coefficients
of alpha are quite different: the second solution is faster,
because the number of fish should be much greater than p (otherwise we
would not bother with a parallel computer!),
and alpha is much larger than beta.
Another way to think about this result is in terms of the memory hierarchy of the machine. Accessing remote memory requires explicit communication and is much more expensive than local memory. The second solution above reduces the number of times we have to access this remote memory (though the total number of words accessed remains about the same). This is analogous to the first assignment, where we saw how important it was to exploit spatial locality, i.e. to use an entire cache line, since it is as expensive to fetch one word as every byte in the cache line.
Now let us think about implementing the second solution, using the block send and receive we have just discussed. The most obvious solution is to try having each processor execute
CMMD_send( (MPROC+1) mod p, ... )
! send to neighbor on right
CMMD_receive( (MPROC-1) mod p, ... )
! receive from neighbor on left
But this solution deadlocks, because no CMMD_send is allowed to
return until a matching receive has occurred. Since everyone is waiting,
no progress is made.
A simple fix is to take two communication steps instead of one: do the odd processors, and then the even processors:
if ( MPROC is even )
CMMD_send( (MPROC+1) mod p, ... )
! send to odd neighbor on right
CMMD_receive( (MPROC-1) mod p, ... )
! receive from odd neighbor on left
else ! ( MPROC is odd )
CMMD_receive( (MPROC-1) mod p, ... )
! receive from even neighbor on left
CMMD_send( (MPROC+1) mod p, ... )
! send to even neighbor on right
endif
However, no such simple solution suffices if instead of a simple rotation,
we wanted to do an arbitrary permutation of our data (see below).
To support these operations, there is another synchronous CMMD routine: CMMD_send_and_receive, which lets the user specify both a message to be sent (to MPROC+1, say) and a message to be received (from MPROC-1, say). However, it does not fix all our problems. In particular, it still requires all processors to synchronize, so that if one processor is "running late", all other processors must wait for it, lowering efficiency. This is analogous to not having any conversations at a party until all latecomers have arrived, rather than letting those already present talk independently.
Indeed, using synchronous send is like calling someone on the telephone, getting put on hold if no one answers, and not being able to hang up or do anything else. Using synchronous receive is like having a telephone that does not ring, and having picked up the phone in anticipation of a call, not being able to do anything other than wait for someone to call. (One can do slightly better by calling CMMD_msg_pending, which says whether an incoming message is pending, before calling CMMD_receive_block.) If the sender and receiver start to use the phone nearly simultaneously, communication is very efficient, but not otherwise.
Nonblocking send, or
CMMD_send_noblock( destination_node, tag, &data, sizeof(data) )sends a message "immediately" by either putting it in the communication network, or saving it in a buffer if the network is busy, and returns right away. There is no guarantee that the message is ever received by any other processor. Asynchronous send, or
CMMD_send_asynch( destination_node, tag, &data, sizeof(data),
handler, handler_argument)
has even weaker guarantees, and less overhead, but puts even more responsibility
on the programmer. CMMD_send_asynch records the user's desire to send a message
in a special location in the system called a
a message control block or MCB.
CMMD_send_asynch() returns a pointer to this MCB.
The system records the status of the message in the MCB, and
the MCB be queried by the user.
There is one MCB allocated per message; it is the user's responsibility to
deallocate the MCB when the message has finally been sent, as described below.
CMMD_send_asynch returns immediately, even if the network is not ready
to receive the data.
In the interest of efficiency, no copy is made of the data in this case,
(copying takes time and space), and it is therefore the user's responsibility not to
overwrite the data before it has been sent. The user can discover whether
the message has been sent in two ways. First, the user can examine the MCB,
by calling either CMMD_msg_done(MCB) or CMMD_all_sends_done(). Second,
the system will automatically call the user-supplied handler procedure
(with arguments MCB and handler_argument) when the message is finally sent.
This is done asynchronously, which you can think of as an interrupt.
The handler procedure can set a flag to indicate the send is done, increment a message
counter, or do most anything else not involving blocking communication.
It should also make sure to free the MCB, which was allocated by the system
at the time of the send; otherwise memory fills up with dead MCBs.
Either blocking or nonblocking sends may be paired either with CMMD_receive_block or an asynchronous receive
CMMD_receive_asynch( source_node, tag, &data, sizeof(data), handler, handler_argument )CMMD_receive_asynch returns immediately after allocating an MCB to keep track of the requested incoming message. As above, the user may query the MCB (via CMMD_msg_done(MCB) or CMMD_all_messages_done()) to see if the message has arrived yet, or let the handler do it, which as before is called when an interrupt announces the arrival of the requested message. Again, the handler must make sure to free the MCB created by the CMMD_receive_asynch call.
The use of nonblocking or asynchronous send and receive permits much more flexibility and efficiency in the design of parallel algorithms, allowing communication in the network to proceed in parallel with computation, without requiring both sending and receiving processors to be at the same place at the same time. Pursuing our earlier telephone analogy, using nonblocking or asynchronous send and receive are similar to leaving messages on an answering machine. But care must be exercised to listen to messages regularly and erase them, before the machine fills up.
CMMD_send_and_receive(
source_node, source_tag, &source_array, sizeof(source_array),
dest_node, dest_tag, &dest_array, sizeof(dest_array) )
The first solution one might try is
CMMD_send_and_receive(
CMMD_any_node, 0, &local_data, sizeof(local_data),
perm(MYPROC), 0, &local_data, sizeof(local_data) )
The problem with this is that local_data may be overwritten by new data
before it is sent out. So one needs to have a second copy:
CMMD_send_and_receive(
CMMD_any_node, 0, &new_local_data, sizeof(local_data),
perm(MYPROC), 0, &local_data, sizeof(local_data) )
This will work, but as we said, it requires all processors to synchronize,
possibly wasting time if they are at different places in the computation.
Now let us try a solution using asynchronous or nonblocking send. Our first attempt is
CMMD_send_asynch( perm(MYPROC), 0, &local_data, sizeof(local_data),
handler, handler_argument)
CMMD_receive_block( CMMD_any_node, 0, &local_data, sizeof(local_data) )
This permits every processor to send as soon as it can, and proceed
as soon as its own data arrives. (Alternatively, we could do
CMMD_receive_asynch if we did not need to use local_data immediately).
But the trouble with this is that local_data could be overwritten
before it is sent out, since CMMD_send_asynch assumes local_data will
be available whenever it needs it. There are two ways to fix this. The
first is to explicitly have a second copy of the local_data:
CMMD_send_asynch( perm(MYPROC), 0, &local_data, sizeof(local_data),
handler, handler_argument)
CMMD_receive_block( CMMD_any_node, 0, &new_local_data, sizeof(local_data) )
and the second is to have an implicit copy, which is needed only if
local_data cannot immediately be pushed into the communication network:
CMMD_send_noblock( perm(MYPROC), 0, &local_data, sizeof(local_data) ) CMMD_receive_block( CMMD_any_node, 0, &new_local_data, sizeof(local_data) )
One node may call
CMMD_bc_to_nodes(&data,sizeof(data)),
and all the other nodes may call
CMMD_receive_bc_from_node(&data,sizeof(data))
in order for the first node to broadcast data to all the others. All
nodes may call
CMMD_reduce_add (or CMMD_reduce_max or ...)
in order to compute the global sum (or max or ...) of the arguments,
and send this value to all the processors. All the nodes may call
CMMD_scan_add (or CMMD_scan_max or ...)
in order to compute the scan or parallel prefix of the indicated
operations. These routines are the CMMD analogues of CMF_SCAN_ADD, etc.,
in CM Fortran. As we described in the solution of Sharks & Fish 2,
CMMD_concat_with_nodes(&local_data, &all_data, sizeof(local_data)
makes a copy of every processor's local_data in all_data on each processor.
CMMD_reset_partition_size(q)
may be used to set the number of processors
equal to any q which is no larger than the actual number of physical
processors. This may be used to help compute speedups for varying
numbers of processors.
There are also routine for collective synchronization.
CMMD_sync_with_nodesis a blocking synchronization call; all processors must eventually call this routine if any one does, and none returns until all have called it.
There are also two asynochronous collective synchronization routines; these depend on a special CM-5 network that is not found on all machines.
CMMD_set_global_or(value)contributes a value to a global-or function, constantly updated by the hardware. This value of the global-or can be fetched by
CMMD_get_global_orBoth functions can be called asynchronously, and as often as you like, from all processors. As long as all the values last set by all the processor are zero, the value returned by CMMD_get_global_or will be 0. As soon as one processor calls CMMD_set_global_or(value) with a nonzero value, the next call to CMMD_get_global_or on any processor will return a nonzero value (after some network delay). This can be used, for example, for a processor to announce to all the others that it has found some common search item that all the other processor were independently searching for, so that the other processors can do some other useful work.