We continue with our discussion of Split-C begun in the last lecture.
global :- local
The difference between store and put is that store provides no
acknowledgement to the sender of the receipt, whereas put does.
This is illustrated by the following figure from the last lecture:
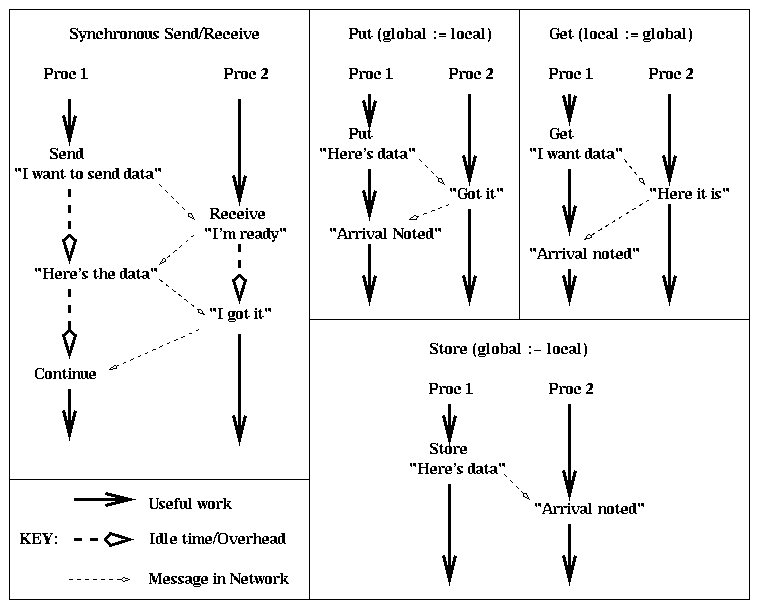
Thus, store reduces yet further the total number of messages in the network, which means the network can spend yet more time sending useful data rather than acknowledgements.
To be able to use the data stored on a processor, one still needs to know whether it has arrived. There are two ways to do this. The simplest way is to call store_sync(n), which waits until n bytes have been stored in the memory of the processor executing store_sync(n). This presumes the parallel algorithm is designed so that one knows how much data to expect.
For example, the following code fragment stores the transpose of the spread array A in B:
static int A[n]::[n], B[n]::[n]
for (i=0; i++; i< n)
B[MYPROC][i] = A[i][MYPROC];
This is a slow implementation because use of "=" in the assignment means
at most one communication occurs at a time.
We may improve this by replacing "=" by ":=":
static int A[n]::[n], B[n]::[n]
for (i=0; i++; i< n)
B[MYPROC][i] := A[i][MYPROC];
sync();
Now there can be several communications going on simultaneously, and one
only has to wait for one's own part of B to arrive before continuing.
But there are still twice as many messages in the network as necessary,
leading us to
static int A[n]::[n], B[n]::[n]
for (i=0; i++; i< n)
B[i][MYPROC] :- A[MYPROC][i];
store_sync(n);
Now there are a minimal number of messages in the system, and one continues
computing as soon as n messages have arrived.
But this code still has a serious bottleneck: the first thing all the processors try to do is send a message to processor 0, which owns B[0][MYPROC] for all MYPROC. This means processor 0 is a serial bottleneck, followed by processor 1 and so on. It is better to have message destinations evenly distributed across all processors. Note that in the following code fragment, for each value of i, the n stores all have different processor destinations:
static int A[n]::[n], B[n]::[n]
for (i=0; i++; i< n)
B[(i+MYPROC) mod MYPROC][MYPROC] :- A[MYPROC][(i+MYPROC) mod MYPROC];
store_sync(n);
It is also possible to ask if all store operations on all processors have completed by calling all_store_sync(). This functions as a barrier, which all processors must execute before continuing. Its efficient implementation depends on some special network hardware on the CM-5 (to be discussed later), and will not necessarily be fast on other machines without similar hardware.
Processor 1 Processor 2
*i = *i + 1 *i = *i + 2
barrier() barrier()
print 'i=', i
Here *i is a global pointer pointing to a location on processor 3.
Depending on the order in which the 4 memory accesses occur
(2 gets of *i and 2 puts to *i), either 'i=1', 'i=2' or
'i=3' may be printed. To avoid this, we encapsulate the
incrementing of *i in an atomic operation, which
guarantees that only one processor may increment *i at a time.
static int x[PROCS]:: ;
void add(int *i, int incr)
{
*a = *a + b
}
splitc_main()
{
int *global i = (int *global)(x+3) /* make sure i points to x[3] */
if ( MYPROC == 3 ) *i = 0; /* initialize *i */
barrier(); /* after this, all processors see *i=0 */
if ( MYPROC == 1 )
atomic( add, i, 1 ); /* executed only by processor 1 */
elseif ( MYPROC == 2 )
atomic( add, i, 2 ); /* executed only by processor 2 */
}
Atomic(procedure, arg1, arg2 ) permits exactly one subroutine to execute
procedure( arg1, arg2 ) at a time. Other processors executing
Atomic(procedure, arg1, arg2 ) at the same time queue up, and are permitted
to execute procedure( arg1, arg2 ) one at at time. Atomic procedures should
be short and simple (since they are by design a serial bottleneck), and
are subject to a number of restrictions described in
section 8.1 of
Introduction to Split-C.
Computer science students who have studied operating systems
will be familiar with this approach, which is called
mutual exclusion, since one processor executing the atomic
procedure excludes all others. The body of the atomic procedure
is also sometimes called a critical section.
Here is a particularly useful application of an atomic operation, called a job queue. A job queue keeps a list of jobs to be farmed out to idle processors. The jobs have unpredictable running times, so if one were to simply assign an equal number of jobs to each processor, some processors might finish long before others and so remain idle. This unfortunate situation is called load imbalance, and is clearly an inefficient use of the machine. The job queue tries to avoid load imbalance by keeping a list of available jobs and giving a new one to each processor after it finishes the last one it was doing. The job queue is a simple example of a load balancing technique, and we will study several others. It assumes all the jobs can be executed independently, so it doesn't matter which processor executes which job.
The simplest (and incorrect) implementation of a job queue one could imagine is this:
static int x[PROCS]:: ;
splitc_main()
{
int job_number;
int *global cnt = (int *global)(x); /* make sure cnt points to x[0] */
if ( MYPROC == 0 ) *cnt = 100; /* initialize *cnt to number of
jobs initially available */
barrier();
while ( *cnt > 0 ) /* while jobs remain to do */
{
job_number = *cnt; /* get number of next available job */
*cnt = *cnt - 1; /* remove job from job queue */
work(job_number); /* do job associated with job_number */
}
The trouble with this naive implementation is that two or more processors may
get *cnt at about the same time and get the same job_number to do. This
can be avoided by decrementing *cnt in a critical section:
static int x[PROCS]:: ;
void fetch_and_add_atomic(int proc, void *return_val, int *addr, int incr_val )
{
int tmp = *addr;
*addr = *addr + incr_val;
atomic_return_i(tmp);
}
int fetch_and_add( int *global addr, int incr_val )
{
return atomic_i( fetch_and_add_atomic, addr, incr_val )
}
splitc_main()
{
int job_number;
int *global cnt = (int *global)(x) /* make sure cnt points to x[0] */
if ( MYPROC == 0 ) *cnt = 100; /* initialize *cnt to number of
jobs initially available */
barrier()
while ( *cnt > 0 ) /* while jobs remain to do */
{
job_number = fetch_and_add(cnt,-1); /* get number of next available job */
work(job_number); /* do job associated with job_number */
}
}
Fetch_and_add(addr,incr_val) atomically fetches the old value of
*addr, and increments it by incr_val.
Find the string "splitc_main" to examine the main procedure. The fish are spread among the processors in a spread array allocated by
fish_t *spread fishes = all_spread_malloc(NFISH, sizeof(fish_t));
Here fish_t is a struct (defined near the top of the file) containing the
position, velocity and mass of a fish, and NFISH = 10000 is a constant.
The next line
int num_fish = my_elements(NFISH)
uses an intrinsic function to return the number of
fish stored on the local processor. Then
fish_t *fish_list = (fish_t *)&fishes[MYPROC];
provides a local pointer to the beginning of the local fish.
In other words, the local fish are stored from address
fish_list to fish_list + num_fish*sizeof(fish_t) -1.
The rest of the main routine calls
all_init_fish (num_fish, fish_list) to initialize the local fish,
all_do_display(num_fish, fish_list) to display the local fish periodically, and
all_move_fish (num_fish, fish_list, dt, &max_acc, &max_speed, &sum_speed_sq)
to move the local fish and return their maximum acceleration, etc.
The global reduction operation
max_acc = all_reduce_to_all_dmax(max_acc);
reduces all the local maximum accelerations to a global maximum. The other two
all_reduce_to_all calls are analogous.
all_init_fish() does purely local work, so let us next examine all_do_display. This routine first declares a spread pointer map, and then calls
map = all_calculate_display(num_fish, fish_list);
to compute the 2D image of the fish in a spread array and return a
spread pointer to it in map. The map is displayed by calling
all_display_fish(map);
to pass the map to the host (which handles the X-window display),
doing a barrier to make sure all the processors have passed their
data to the host, and then having only processor 0 display the data via
on_one {X_show();}
all_calculate_display works as follows. on the first call, a spread array of size DISPLAY_SIZE-by-DISPLAY_SIZE (256-by-256) is allocated, with map pointing to it. The statements
for_my_1d(i, DISPLAY_SIZE*DISPLAY_SIZE) {
map[i] = 0; /* blue */ }
barrier();
have each processor initialize its local entries of the spread array to 0
(blue water, i.e. no fish). The Split-C macro for_my_1d loops over just
those values of i from 0 to DISPLAY_SIZE*DISPLAY_SIZE-1 such that
map[i] is stored locally.
The next loop loops over all locally stored fish, computes the scaled coordinates (x_disp,y_disp) of each fish, where 0 <= x_disp , y_disp < DISPLAY_SIZE, and atomically adds 1 to map[x_disp,y_disp] to indicate the presence of a fish at that location (we use poetic license here by addressing map as a 2D array, whereas the code addresses it as a 1D array). The final all_atomic_sync waits until all the processors have finished updating map.
After all_calculate_display returns in all_do_display, map contains an image of the current fish positions, with map[x_disp,y_disp] containing the number of fish at scaled location (x_disp,y_disp). Next, all_do_display calls all_display_fish(map) to transfer the data to the host. The first time all_display_fish is called it has processor 0 initialize the X-window interface, allocates a spread array called old_map to keep a copy of the map from the previous time step, and initializes old_map to 0 (empty). Then, all_display_fish has each processor compare the part of map it owns to the corresponding part of old_map, which it also owns, and if they differ it transfers the new map data to the host for X-window display. This minimizes the number of messages the host has to handle, a serial bottleneck. Finally, map is copied to old_map for the next step.
Procedure all_move_fish does all the work of moving the fish, and is purely local.