Split-C was designed at Berkeley, and is intended for distributed memory multiprocessors. It is a small SPMD extension to C, and meant to support programming in data parallel, message passing and shared memory styles. Like C, it is "close" to the machine, so understanding performance is relatively easy. The best document from which to learn Split-C is the tutorial Introduction to Split-C. There is a debugger available as well: Mantis.
We begin with a general discussion of Split-C features, and then discuss the solution to Sharks & Fish problem 1 in detail. The most important features of Split-C are
int *Pl, *Pl1, *Pl2 /* local pointers */
int *global Pg, Pg1, Pg2 /* global pointers */
int *spread Ps, Ps1, Ps2 /* spread pointers */
The following assignment sends messages to fetch the data pointed to by
Pg1 and Pg2, brings them back, and stores their sum locally:
*Pl = *Pg1 + *Pg2
Execution does not continue until the entire operation is complete.
Note that the program on the processors owning the data pointed to by
Pg1 and Pg2 does not have to cooperate in this communication in any explicit
way; it happens "automatically", in effect interrupting
the processors owning the remote data, and letting them continue.
In particular, there
is no notion of needing matched sends and receives as in a message passing
programming style. Rather than calling this send or receive,
the operation performed is called a get, to emphasize that the
processor owning the data need not anticipate the request for data.
The following assignment stores data from local memory into a remote location:
*Pg = *Pl
As before, the processor owning the remote data need not anticipate the arrival
of the message containing the new value. This operation is called a
put.
Global pointers permit us to construct distributed data structures which span the whole machine. For example, the following is an example of a tree which spans processors. The nodes of this binary tree can reside on any processor, and traversing the tree in the usual fashion, following pointers to child nodes, works without change.
typedef struct global_tree *global gt_ptr
typedef struct global_tree{
int value;
gt_ptr left_child;
gt_ptr right_child;
} g_tree
We will discuss how to design good distributed data struction later
when we discuss the
Multipol library.
Global pointers offer us the ability to write more complicated and flexible programs, but also get new kinds of bugs. The following code illustrates a race condition, where the answer depends on which processor executes "faster". Initially, processor 3 owns the data pointed to by global pointer i, and its value is 0:
Processor 1 Processor 2
*i = *i + 1 *i = *i + 2
barrier() barrier()
print 'i=', i
It is possible to print out i=1, i=2 or i=3, depending on the order in
which the 4 global accesses to i occur. For example, if
processor 1 gets *i (=0) processor 2 gets *i (=0) processor 1 puts *i (=0+1=1) processor 2 puts *i (=0+2=2)then the processor 1 will print "i=2". We will discuss programming styles and techniques that attempt to avoid this kind of bug.
A more interesting example of a potential race condition is in a job queue, a data structure for distributing chunks of work of unpredictable sizes to different processors. We will discuss this example below after we present more feature of Split-C.
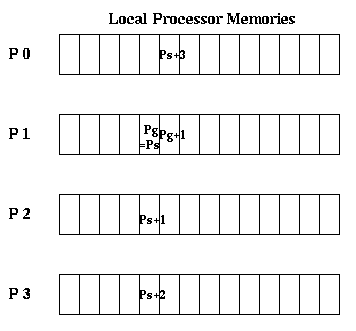
Global pointers may be incremented like local pointers: if Pg = (processor,offset), then Pg+1 = (processor,offset+1). This lets one index through a remote part of a data structure. Spread pointers differ from global pointers only in this respect: if Ps = (processor,offset), then
Ps+1 = (processor+1 ,offset) if processor < PROCS-1, or
= (0 ,offset+1) if processor = PROCS-1
where PROCS is the number of processors.
In other words, viewing the memory as a 2D array, with one
row per processor and one column per local memory location, incrementing
Pg moves the pointer across a row, and incrementing Ps moves the pointer
down a column. Incrementing Ps past the end of a column moves Ps to the
top of the next columns.
The local part of a global or spread pointer may be extracted using the function to_local.
Only local pointers may be used to point to procedures; neither global nor spread pointers may be used this way. There are also some mild restrictions on use of deferenced global and spread pointers; see the last section of the Split-C tutorial.
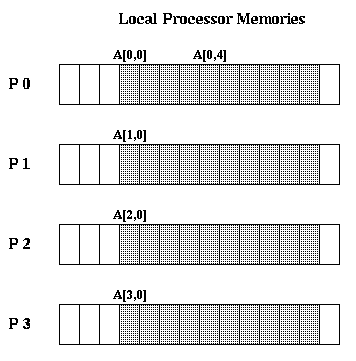
static int A[PROCS]::[10]
declares an array of 10 integers in each processor memory.
The double colon is called the spreader, and indicated that
subscripts to its left index across processors, and subscripts
to the right index within processors. So for example
A[i,j] is stored in location to_local(A)+j on processor i.
In other words, the 10 words on each processor reside at the
same local memory locations.
The declaration
static double A[n][m]::[b][b]
declares a total of n*m*b^2 ints. You may think of this as
n*m groups of b^2 doubles being allocated to the processors
in round robin fashion. The memory per processor is
8*b^2*ceiling(n*m/PROCS), so if PROCS does not evenly
divide n*m, some memory will be wasted.
A[i][j][k][l] is stored in processor i*m+j mod PROCS, and
at offset to_local(A) + 8*b^2*floor( (i*m+j)/PROCS ) + k*b+l
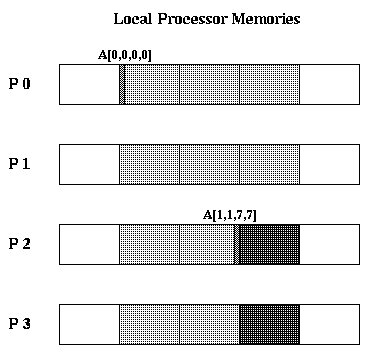
In the figure below, we illustrate the layout of A[2][5]::[7][7].
Each wide light gray rectangle represents 49 double words. The two
wide dark gray rectangles represent wasted space. The two thin
medium gray rectangles are the very first word, A[0][0][0][0],
and A[1][1][7][7], respectively.
In addition to declaring static spread arrays, one can malloc them:
int *spread w = all_spread_malloc(10, sizeof(int))This is a synchronous, or blocking, subroutine call (like the first kind of send and receive we discussed in Lecture 6)), so all processors must participate, and should do so at about the same time to avoid making processors wait idly, since all processors will wait until all processors have called it. The value returned in w is a pointer to the first word of the array on processor 0:
w = (0, local address of first word on processor 0).
(A nonblocking version, int *spread w = spread_malloc(10, sizeof(int)), executes on just one processor, but allocates the same space as before, on all processors. Some internal locking is needed to prevent allocating the same memory twice, or even deadlock. However, this only works on the CM-5 implementation and its use is discouraged.)
a := *global_pointer
... other work not involving a ...
synch()
b = b + a
where a and b are local variables,
initiates a get of the data pointed to by global_pointer, does other useful
work, and only waits for a's arrival, by calling synch(), when a is
really needed. This is also called prefetching.
The statement
*global_pointer := b
similarly launches a put of the local data b into the remote location
global_pointer, and immediately continues computing. One call also wait
until an acknowledgement is received from the processor receiving
b, by calling synch().
Being able to initiate a remote read (or get) and remote write (or put), go on to do other useful work while the network is busy delivering the message and returning any response, and only waiting for completion when necessary, offers several speedup opportunities.