Indirect methods combine a predictive forward model that recovers an estimate of absolute state with a conventional MDP learning method. Given absolute state, recovering an optimal policy for a MDP is a well-studied problem. Q-Learning is one widely used reinforcement learning method for finding an optimal MDP policy. The Q function maps state and action pairs to a utility value, which is the expected discounted future reward given that state and action. Optimal utility values can be computed on-line using a Temporal Differences method [25], which is an incremental form of a full Dynamic Programming approach [5]. In the case of deterministic state transitions, to maximize Eq. (1) the optimal Q function must satisfy
| (2) |
| (3) |
Several approaches have been proposed which combine a predictive model to transform a POMDP to a MDP and then use Q-learning to construct a policy function. The Perceptual Distinctions Approach (PDA) developed by Chrisman [8] uses a state-splitting approach to construct a model of the domain. A modified Expectation-Minimization algorithm was used to alternate between maximizing the model probability given a fixed number of internal states, and splitting perceptually aliased states into new states. A similar method was developed by McCallum, the Utile Distinction Memory approach (UDM), which split states based on the predicted reward [19]. Given a state estimator learned via PDA or UDM, or simply computed from T and O, an optimal policy can be constructed [7]. However these indirect methods have been criticized as being computationally intractable in realistic environments [14]. Indeed, the empirical results suggest that a prohibitive amount of training time is required with these algorithms [20].
Rather than convert a POMDP to a MDP through state estimation, direct methods update a value function over observations without recovering absolute state. Jaakkola et. al. present a Monte-Carlo algorithm for policy evaluation and improvement using Q-values defined over actions and observations [14]. They provide a recursive formulation of the Monte-Carlo algorithm, and prove the policy improvement method will converge to at least a local maximum.
A hybrid approach sharing both direct and indirect qualities has been explored by Lin [16] and McCallum [20]. These methods use a memory-based approach to identifying state. Lin's window-Q algorithm supplies a history of the N most recent observations and actions to a conventional Q-learning algorithm. The intuition is that perceptually aliased states can be discriminated by indexing utility over a vector of recent experience. A significant drawback to this approach is the use of fixed window size. McCallum's Instance-Based state identification method extends this approach to use windows of varying length, using a sequence matching criterion with a K-nearest neighbor utility representation.
The memory-based approach to hidden-state reinforcement learning can be successfully applied to our AGR task, once we generalize the the nearest-neighbor algorithm. As described in Section 3.2, we modify the nearest neighbor computation to pool all experience whose similarity (e.g., sequence match length) is approximately equal to the K'-th percentile rank, rather than simply using the K largest similarity scores. This is important in domains where the world is non-stationary, such as with rapidly changing target and distractor patterns; in this case we need to average all experiences with a particular sequence of observations when computing utility. We first describe the basic memory-based, hidden-state reinforcement learning algorithm, and then present our extensions.
![[*]](foot_motif.gif)
If full access to the state were available and a table were used to represent Q values, this would simply be a table look-up operation, but we do not have full access to the state, nor are we using a table representation. Instead, utility is associated with the implicit state that the system was in at the previous time point. Using McCallum's Nearest Sequence Memory (NSM) algorithm, we find the $K$ nearest neighbors in the history list for a given action, and compute their average Q value.
Nearest neighbors are computed using a sequence match criterion; we look to prior experiences that are most similar to the current time point, in terms of having had the same preceding sequence of actions and observations. For each element on the history list, we compute the sequence match criterion with the current time point, M(i,T), where M(i,j) indicates the number of action and observations that overlap between the sequence ending at time i and the sequence ending at time j:
| (4) |
For each candidate action, we compute the K most similar previous experiences that were then followed by the candidate action. Using a superscript in parentheses to denote the action index of a Q-value, we then compute
![\begin{displaymath}Q^{(a^*)}[T] = (1/K)\sum_{i=0}^T v^{(a^*)}[i]q[i] ~,\end{displaymath}](img38.gif) |
(5) |
Given Q values for each action the optimal policy is simply
| (6) |
In either case, the action is executed yielding an observation and reward,
and a new tuple added to the history. The new Q-value is set to be the
Q value of the chosen action, q[T+1]=Q(a[T+1])[T].
The update step of Q learning is then computed, evaluating
| (7) |
| (8) |
This poses a problem for the instance-based algorithm defined above, which finds voting instances using a strict K-nearest neighbor method, since it depends critically on choosing the correct value of K. A value which is too small will miss some relevant experience, and yield an unreliable utility estimate; a value which is too large will merge together instances which are actually different states, returning us to the problem of perceptual aliasing. Since the number of instances (memories) which are relevant to a particular utility estimate may vary greatly depending on the distribution of target and distractor trials, no fixed value of K will suffice.
A simple example illustrates the problem: consider the estimation of the utility of accept when the previous observation/action sequence was to foveate the face and observe a neutral expression. Assume that the target and all distractors all have a face with neutral expression, so this should be of no use in discriminating target from distractor. During the training phase the system will likely have explored this sequence several times, some with the target and some with the distractor. When match similarities are computed, the memories with maximum match value will indeed all correspond to the relevant previous experience. There may be 20 such previous experiences, but a strict K-nearest neighbor algorithm with K=4 will ignore 16 of them. If these 4 memories happen to miss experiences with the target, which is not unlikely, then the computed utility will be incorrect.
Rather than set K very large and risk merging truly different states, we instead propose a new algorithm, which we call Variable-K Nearest Neighbors. Variable-K differs from Strict-K in that all memories with a given match length are included in the voting set, e.g., are pooled together when estimating utility.
In the Variable-K algorithm, we assert a minimum percentage kp
of experience to be included. (If there is no noise in the match function,
this can be effectively set to zero; in our experiments we used ![]() )
We histogram the match lengths of all memories, and sort them from largest
to smallest. We then find the match length value m' such that the
)
We histogram the match lengths of all memories, and sort them from largest
to smallest. We then find the match length value m' such that the ![]() of memories have larger match lengths than m'. We then subtract
a fixed amount kt to this match length value, and include all memories
with match value greater than m'-kt into the voting set.
of memories have larger match lengths than m'. We then subtract
a fixed amount kt to this match length value, and include all memories
with match value greater than m'-kt into the voting set.
The effect of this algorithm is to find a percentage of nearest neighbors
with largest match values, as does strict-K, but then to include all other
memories with roughly the same match length. In the above example, all
20 experiences would be included in the voting set, and utility accurately
estimated. In practice we have used kt=1, and found this algorithm
greatly improved the performance of instance based Q-learning given the
multiple trial (e.g. non-stationary world) structure of our AGR task.
With the Variable-K enhancement, instance-based Q-learning can find
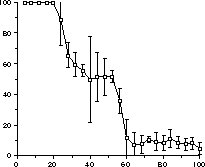
optimal policies to solve AGR tasks. Figure 2
shows the results using this hidden-state Q-learning algorithm on an AGR
task using image-based world state. In this example four different world
states were used for the target and distractors; varying amounts of noise
were added to the actual observations at run-time. We ran the system by
randomly selecting one of the patterns as target, and using the other three
as distractors. This Q-learning system easily learns the correct foveation
policies to actively recognize these targets; e.g., to foveate down to
recognize one of the square targets, and to foveate up to recognize one
of the circle targets. For moderate levels of noise, each pattern can be
easily discriminated from all the others, however, as ![]() exceeds 20.0,
the high-resolution information in the signal becomes insufficient to discriminate
the two square targets and the two circle target, so performance drops
by half. As
exceeds 20.0,
the high-resolution information in the signal becomes insufficient to discriminate
the two square targets and the two circle target, so performance drops
by half. As ![]() approaches 60.0, the low-resolution information becomes indistinguishable,
and all the targets are confused, leading to a recognition rate of zero.
approaches 60.0, the low-resolution information becomes indistinguishable,
and all the targets are confused, leading to a recognition rate of zero.
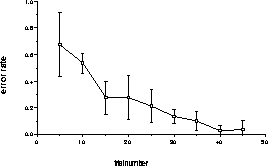
Successful policies were also found for the interactive interface domain.
Figure 3 shows the recognition performance
on the set of gestures shown in Figure 1(c,d).
These patterns were quite simple; and convergence to an accurate recognition
policy is straightforward. For more complicated targets, it is possible
for the random policy search to converge prematurely to a local maxima
of Equation (1), which can correspond to good
performance but still have errors. While there are many strategies for
focusing search in a structured manner and overcoming local minima, we
have implemented a simple strategy: we detect local minima and restart
the learning process with a new random seed when premature convergence
is found. We detect convergence by examining average recognition error
over a window of (Nc=100) recent of trials: if during
the entire window average the error rate has remained fixed, was above
an upper threshold (![]() )
or below a lower threshold (
)
or below a lower threshold (![]() ),
we declare the algorithm converged. We then test Nc subsequent
trials; if an error is detected we determine that this was a local minima,
and restart the learning process, clearing experience memory and beginning
again with a new random seed (which affects both the sequence of target/distractor
patterns and the exploration actions chosen.) Additionally if we exceed
a fixed maximum memory length (Ml=10000), we restart
learning. This algorithm is suboptimal in terms of learning time, but does
find correct recognition policy solutions. In the following section we
address the issue of how to extract a more efficient run-time representation
from these learned policies.
),
we declare the algorithm converged. We then test Nc subsequent
trials; if an error is detected we determine that this was a local minima,
and restart the learning process, clearing experience memory and beginning
again with a new random seed (which affects both the sequence of target/distractor
patterns and the exploration actions chosen.) Additionally if we exceed
a fixed maximum memory length (Ml=10000), we restart
learning. This algorithm is suboptimal in terms of learning time, but does
find correct recognition policy solutions. In the following section we
address the issue of how to extract a more efficient run-time representation
from these learned policies.
 |



 (b)
(b)