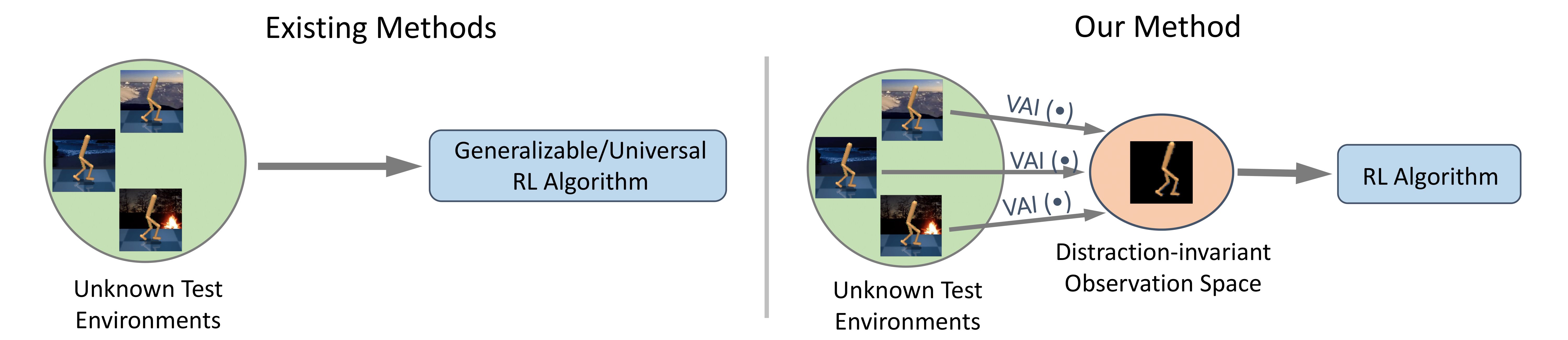
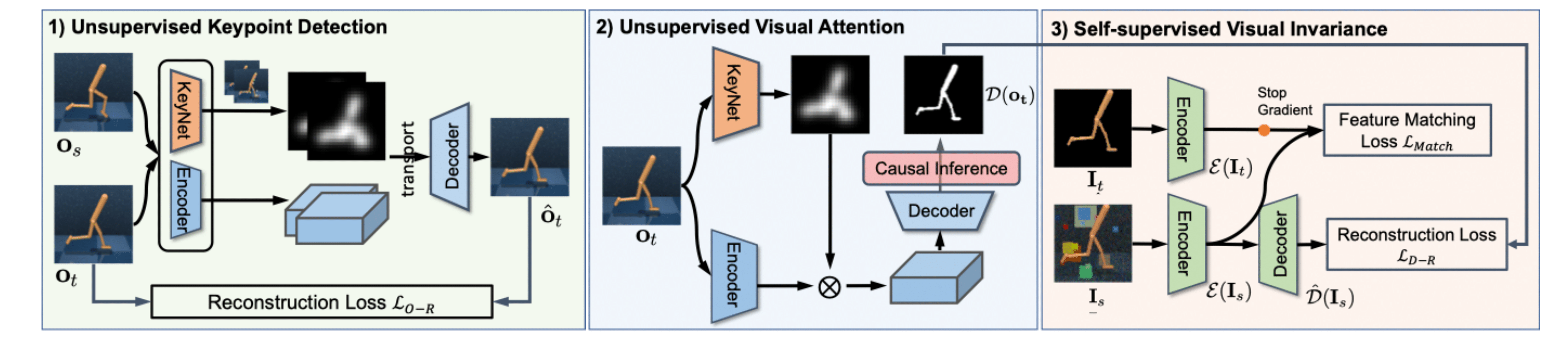
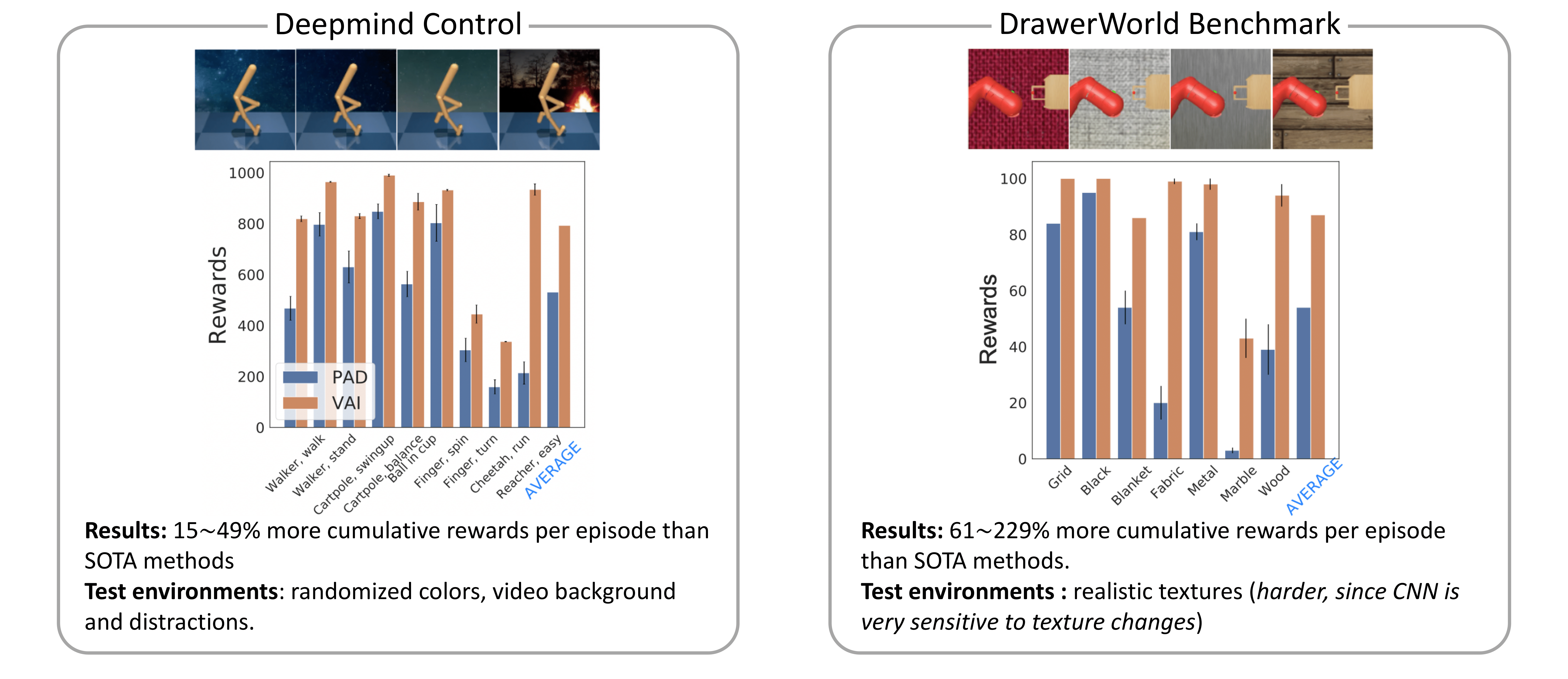
Unsupervised Visual Attention and Invariance for Reinforcement Learning
Xudong Wang*
Lian Long*
Stella Yu
UC Berkeley / ICSI
[Preprint]
[PDF]
[Code]
[Citation]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021)