2024
[New] G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis
Yufei Ye, Abhinav Gupta, Kris Kitani, Shubham Tulsiani
CVPR, 2024
pdf project page bibtex

[New] MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Hanzhe Hu*, Zhizhuo Zhou*, Varun Jampani, Shubham Tulsiani
CVPR, 2024
pdf project page bibtex code
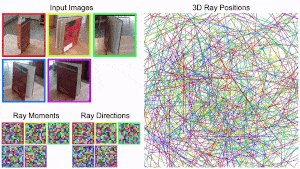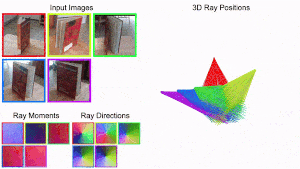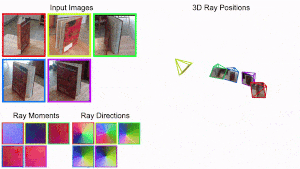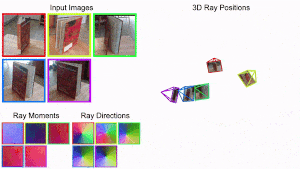
[New] Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang*, Amy Lin*, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, Shubham Tulsiani
ICLR, 2024
pdf project page bibtex code

[New] Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Homanga Bharadhwaj, Abhinav Gupta*, Vikash Kumar*, Shubham Tulsiani*
ICRA, 2024 (Finalist for Best Paper Award in Robot Manipulation)
pdf project page bibtex
[New] RoboAgent: Towards Sample Efficient Robot Manipulation with Semantic Augmentations and Action Chunking
Homanga Bharadhwaj*, Jay Vakil*, Mohit Sharma*, Abhinav Gupta, Shubham Tulsiani, Vikash Kumar
ICRA, 2024
pdf project page bibtex data

RelPose++: Recovering 6D Poses from Sparse-view Observations
Amy Lin*, Jason Y. Zhang*, Deva Ramanan, Shubham Tulsiani
3DV, 2024
pdf project page bibtex code
2023

Diffusion-Guided Reconstruction of Everyday Hand-Object Interaction Clips
Yufei Ye, Poorvi Hebbar, Abhinav Gupta, Shubham Tulsiani
ICCV, 2023
pdf project page bibtex code

Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Jianren Wang*, Sudeep Dasari*, Mohan Kumar Srirama, Shubham Tulsiani, Abhinav Gupta
ICCV, 2023
pdf project page bibtex code
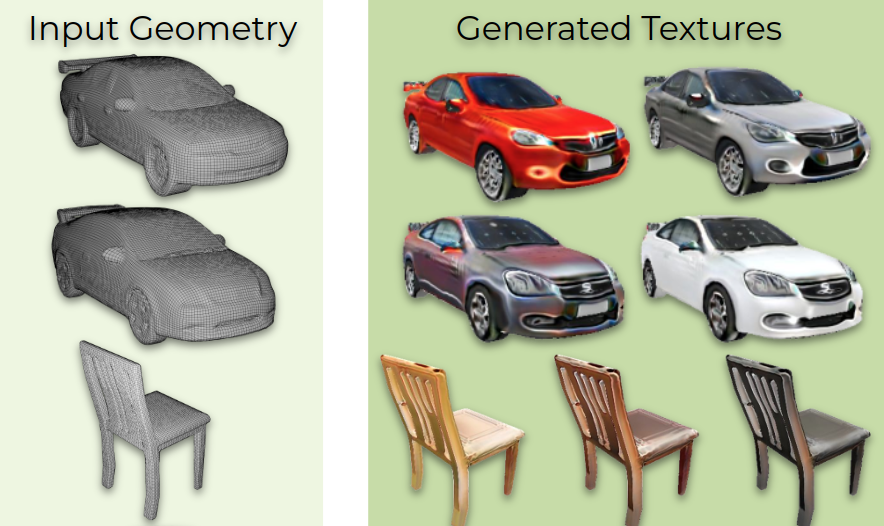
Mesh2Tex: Generating Mesh Textures from Image Queries
Alexey Bokhovkin, Shubham Tulsiani, Angela Dai
ICCV, 2023
pdf project page bibtex
Visual Affordance Prediction for Guiding Robot Exploration
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tulsiani
ICRA, 2023
pdf project page bibtex code
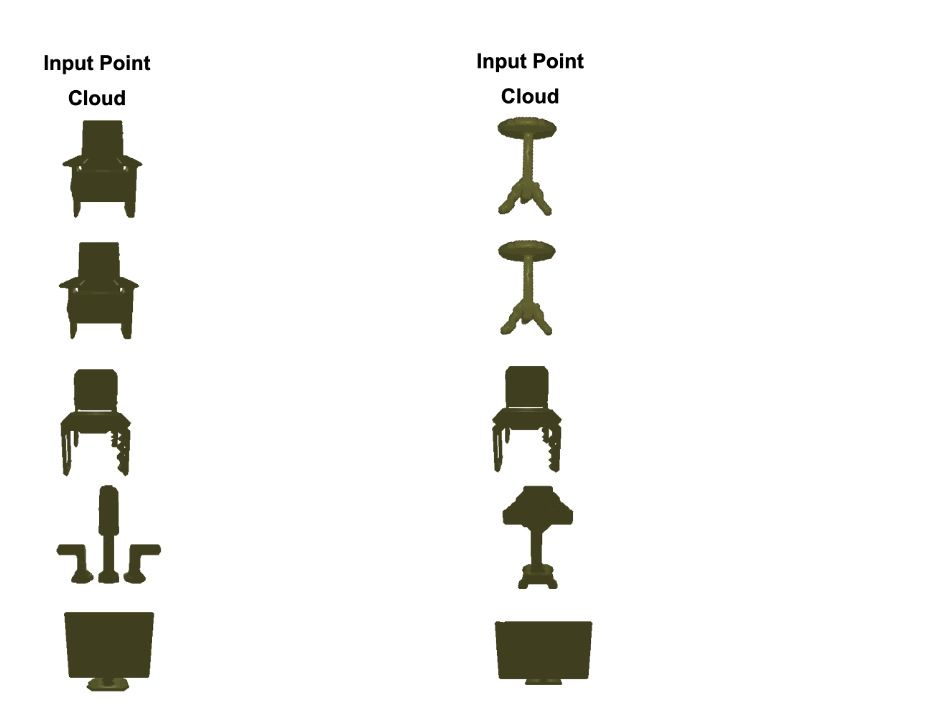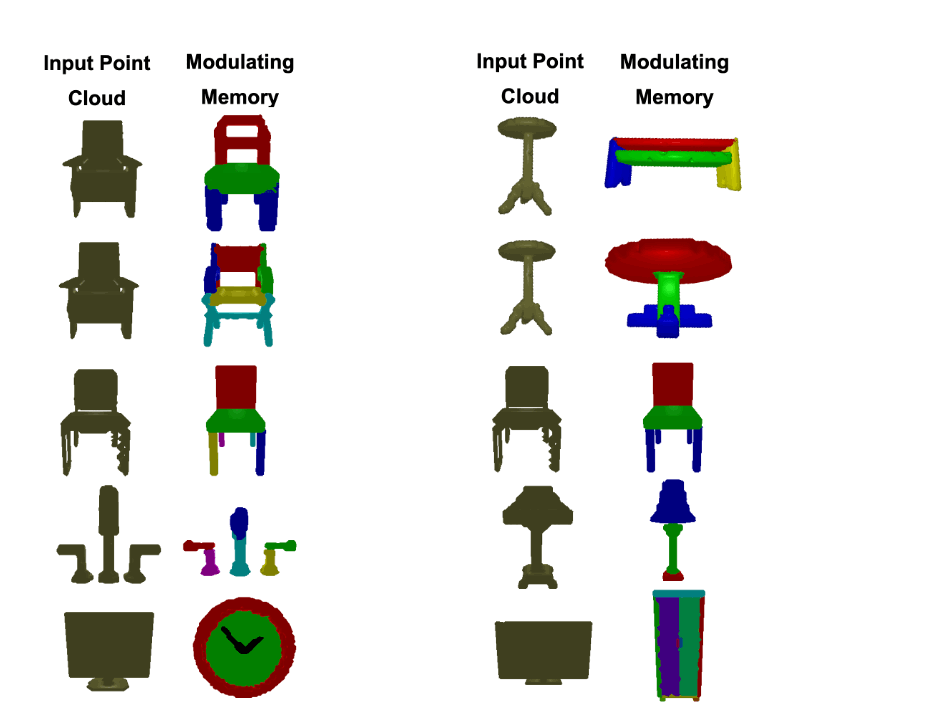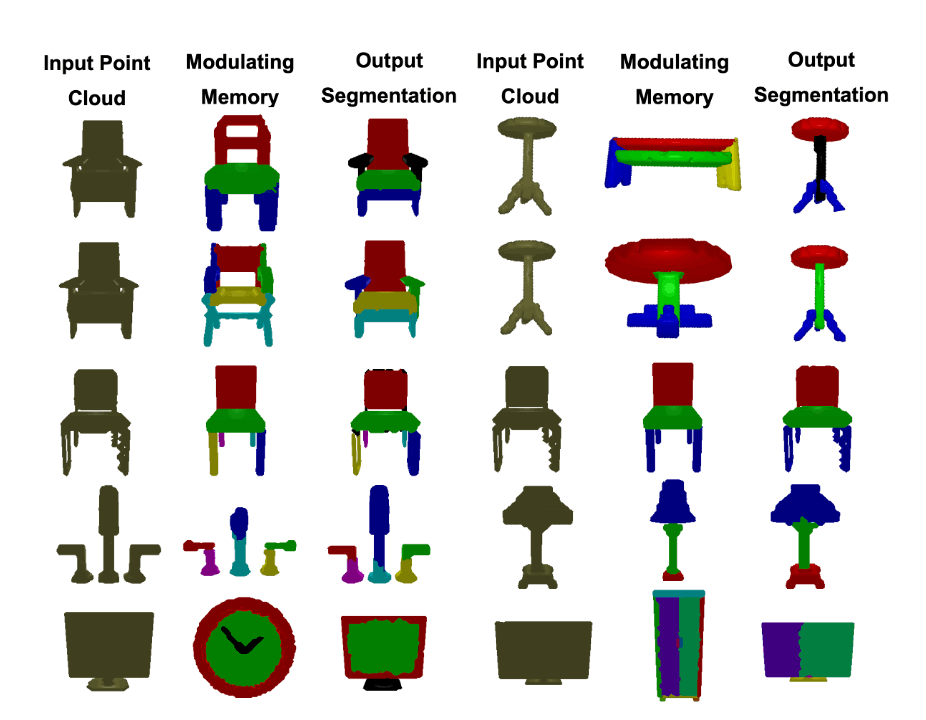
Analogy-Forming Transformers for Few-Shot 3D Parsing
Nikolaos Gkanatsios*, Mayank Singh*, Zhaoyuan Fang, Shubham Tulsiani, Katerina Fragkiadaki
ICLR, 2023
pdf project page bibtex code

SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction
Zhizhuo Zhou, Shubham Tulsiani
CVPR, 2023
pdf project page bibtex code

Affordance Diffusion: Synthesizing Hand-Object Interactions
Yufei Ye, Xueting Li, Abhinav Gupta, Shalini De Mello, Stan Birchfield, Jiaming Song, Shubham Tulsiani, Sifei Liu
CVPR, 2023
pdf project page bibtex
2022
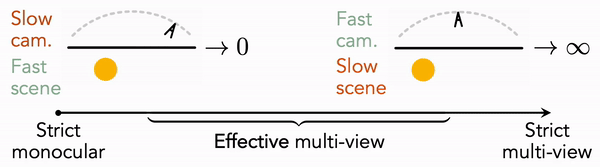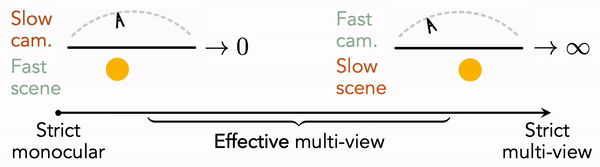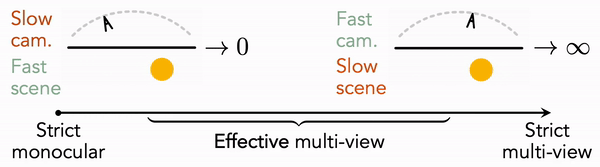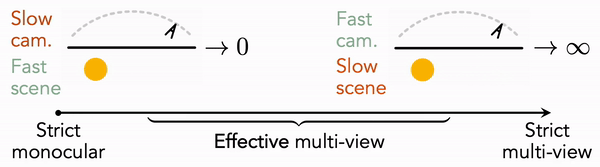
Monocular Dynamic View Synthesis: A Reality Check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, Angjoo Kanazawa
NeurIPS, 2022
pdf project page bibtex code
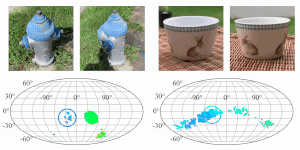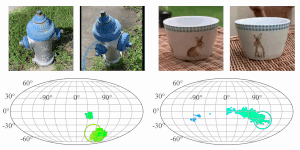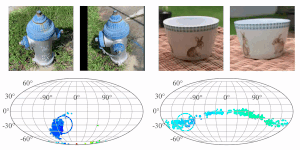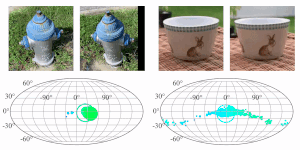
RelPose: Predicting Probabilistic Relative Rotation for Single Objects in the Wild
Jason Y. Zhang, Deva Ramanan, Shubham Tulsiani
ECCV, 2022
pdf project page bibtex code

Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction
Kalyan Vasudev Alwala, Abhinav Gupta, Shubham Tulsiani
CVPR, 2022
pdf project page bibtex code

What's in your hands? 3D Reconstruction of Generic Objects in Hands
Yufei Ye, Abhinav Gupta, Shubham Tulsiani
CVPR, 2022
pdf project page bibtex code

AutoSDF: Shape Priors for 3D Completion, Reconstruction and Generation
Paritosh Mittal*, Yen-Chi Cheng*, Maneesh Singh, Shubham Tulsiani
CVPR, 2022
pdf project page bibtex code
2021

NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
Jason Y. Zhang, Gengshan Yang, Shubham Tulsiani*, and Deva Ramanan*
NeurIPS, 2021
pdf project page bibtex video code

No RL, No Simulation: Learning to Navigate without Navigating
Meera Hahn, Devendra Chaplot, Shubham Tulsiani, Mustafa Mukadam, James M. Rehg, Abhinav Gupta
NeurIPS, 2021
pdf project page bibtex code
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation
Bernardo Aceituno, Alberto Rodriguez, Shubham Tulsiani, Abhinav Gupta, Mustafa Mukadam
CoRL, 2021
pdf bibtex

Where2Act: From Pixels to Actions for Articulated 3D Objects
Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta, Shubham Tulsiani
ICCV, 2021
pdf project page bibtex code

PixelTransformer: Sample Conditioned Signal Generation
Shubham Tulsiani, Abhinav Gupta
ICML, 2021
pdf project page bibtex code

Shelf-Supervised Mesh Prediction in the Wild
Yufei Ye, Shubham Tulsiani, Abhinav Gupta
CVPR, 2021
pdf project page bibtex code
2020
See, Hear, Explore: Curiosity via Audio-Visual Association
Victoria Dean, Shubham Tulsiani, Abhinav Gupta
NeurIPS, 2020
pdf project page bibtex video code

Visual Imitation Made Easy
Sarah Young, Dhiraj Gandhi, Shubham Tulsiani, Abhinav Gupta, Pieter Abbeel, Lerrel Pinto
CORL, 2020
pdf project page bibtex video code

Articulation-aware Canonical Surface Mapping
Nilesh Kulkarni, Abhinav Gupta, David Fouhey, Shubham Tulsiani
CVPR, 2020
pdf project page bibtex video code
Use the Force, Luke! Learning to Predict Physical Forces by Simulating Effects
Kiana Ehsani, Shubham Tulsiani, Saurabh Gupta, Ali Farhadi, Abhinav Gupta
CVPR, 2020
pdf project page bibtex code
Intrinsic Motivation for Encouraging Synergistic Behavior
Rohan Chitnis, Shubham Tulsiani, Saurabh Gupta, Abhinav Gupta
ICLR, 2020
pdf project page bibtex

Discovering Motor Programs by Recomposing Demonstrations
Tanmay Shankar, Shubham Tulsiani, Lerrel Pinto, Abhinav Gupta
ICLR, 2020
pdf bibtex

Efficient Bimanual Manipulation using Learned Task Schemas
Rohan Chitnis, Shubham Tulsiani, Saurabh Gupta, Abhinav Gupta
ICRA, 2020
preprint bibtex video
2019
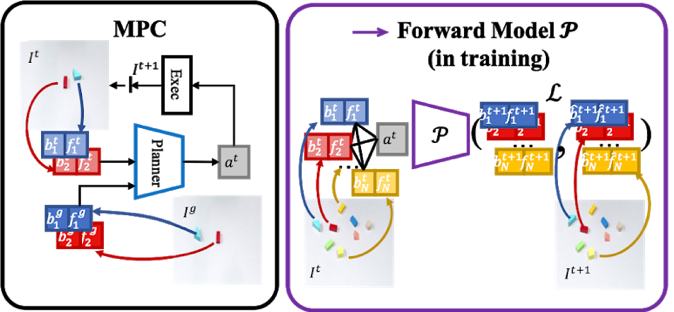
Object-centric Forward Modeling for Model Predictive Control
Yufei Ye, Dhiraj Gandhi, Abhinav Gupta, Shubham Tulsiani
CORL, 2019
pdf project page bibtex
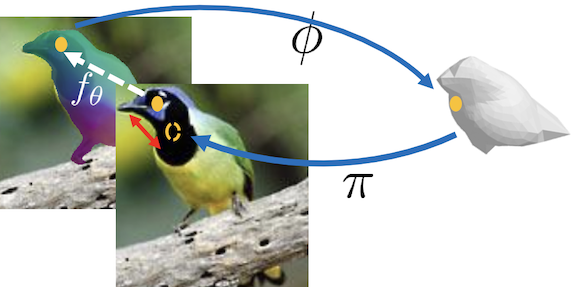
Canonical Surface Mapping via Geometric Cycle Consistency
Nilesh Kulkarni, Abhinav Gupta*, Shubham Tulsiani*
ICCV, 2019
pdf project page bibtex video code

Compositional Video Prediction
Yufei Ye, Maneesh Singh, Abhinav Gupta*, Shubham Tulsiani*
ICCV, 2019
pdf project page bibtex code

3D-RelNet: Joint Object and Relational Network for 3D Prediction
Nilesh Kulkarni, Ishan Misra, Shubham Tulsiani, Abhinav Gupta
ICCV, 2019
pdf project page bibtex code

Order-Aware Generative Modeling Using the 3D-Craft Dataset
Zhuoyuan Chen*, Demi Guo*, Tong Xiao*, et. al.
ICCV, 2019
pdf bibtex

Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
Tejas Khot*, Shubham Agrawal*, Shubham Tulsiani, Christoph Mertz, Simon Lucey, Martial Hebert
arXiv preprint, 2019
pdf project page bibtex code
2018

Layer-structured 3D Scene Inference via View Synthesis
Shubham Tulsiani, Richard Tucker, Noah Snavely
ECCV, 2018
pdf project page bibtex code
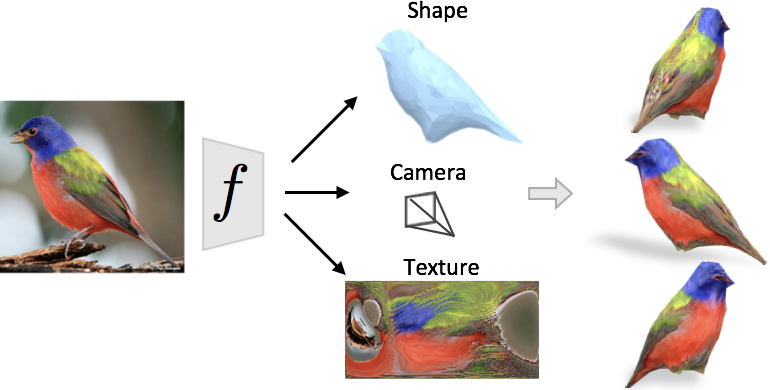
Learning Category-Specific Mesh Reconstruction from Image Collections
Angjoo Kanazawa*, Shubham Tulsiani*, Alexei A. Efros, Jitendra Malik
ECCV, 2018
pdf project page bibtex video code

Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction
Shubham Tulsiani, Alexei A. Efros, Jitendra Malik
CVPR, 2018
pdf project page bibtex code

Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene
Shubham Tulsiani, Saurabh Gupta, David Fouhey, Alexei A. Efros, Jitendra Malik
CVPR, 2018
pdf project page bibtex code
2017

Hierarchical Surface Prediction for 3D Object Reconstruction
Christian Häne, Shubham Tulsiani, Jitendra Malik
3DV, 2017
pdf bibtex slides code
2016

Learning Category-Specific Deformable 3D Models for Object Reconstruction
Shubham Tulsiani*, Abhishek Kar*, João Carreira, Jitendra Malik
TPAMI, 2016
pdf bibtex code

View Synthesis by Appearance Flow
Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, Alexei A. Efros
ECCV, 2016
pdf bibtex code
2015

Pose Induction for Novel Object Categories
Shubham Tulsiani, João Carreira, Jitendra Malik
ICCV, 2015
pdf bibtex code
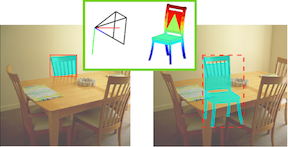
Amodal Completion and Size Constancy in Natural Scenes
Abhishek Kar, Shubham Tulsiani, João Carreira, Jitendra Malik
ICCV, 2015
pdf bibtex

Viewpoints and Keypoints
Shubham Tulsiani, Jitendra Malik
CVPR, 2015
pdf bibtex code

Category-Specific Object Reconstruction from a Single Image
Abhishek Kar*, Shubham Tulsiani*, João Carreira, Jitendra Malik
CVPR, 2015 (Best Student Paper Award)
pdf project page bibtex code

Virtual View Networks for Object Reconstruction
João Carreira, Abhishek Kar, Shubham Tulsiani, Jitendra Malik
CVPR, 2015
pdf bibtex video code
2013
A colorful approach to text processing by example
Kuat Yessenov, Shubham Tulsiani, Aditya Menon, Robert C Miller, Sumit Gulwani, Butler Lampson, Adam Kalai
UIST, 2013
pdf bibtex