Can LLMs Follow Simple Rules?
- Norman Mu1
- Sarah Chen2,3
- Zifan Wang2
- Sizhe Chen1
- David Karamardian2
- Lulwa Aljeraisy4
- Basel Alomair4
- Dan Hendrycks2
- David Wagner1
1UC Berkeley 2Center for AI Safety 3Stanford 4King Abdulaziz City for Science and Technology
Abstract
As Large Language Models (LLMs) are deployed with increasing real-world responsibilities, it is important to be able to specify and constrain the behavior of these systems in a reliable manner. Model developers may wish to set explicit rules for the model, such as ``do not generate abusive content'', but these may be circumvented by jailbreaking techniques. Existing evaluations of adversarial attacks and defenses on LLMs generally require either expensive manual review or unreliable heuristic checks. To address this issue, we propose Rule-following Language Evaluation Scenarios (RuLES), a programmatic framework for measuring rule-following ability in LLMs. RuLES consists of 14 simple text scenarios in which the model is instructed to obey various rules while interacting with the user. Each scenario has a programmatic evaluation function to determine whether the model has broken any rules in a conversation. Our evaluations of proprietary and open models show that almost all current models struggle to follow scenario rules, even on straightforward test cases. We also demonstrate that simple optimization attacks suffice to significantly increase failure rates on test cases. We conclude by exploring two potential avenues for improvement: test-time steering and supervised fine-tuning.
Example test case failures of GPT-4, Claude 3, and Llama-2 Chat 70B.
Scenarios
RuLES contains 14 text-based scenarios, each of which requires the assistant model to operate while following one or more rules.
The scenarios are inspired by desirable security properties of computer systems and children's games.
RuLES is built from:
- Scenarios : evaluation environments consisting of instructions and rules expressed in English, as well as a corresponding evaluation function that detects rule violations. Instructions and rules may reference scenario parameters (e.g., a secret key) which must be sampled to define a concrete "scenario instance" for evaluation.
-
Rules : definitions of required behaviors for the model. Scenarios may contain multiple rules, which we categorize as either harmless rules, which define what the model must not do, or helpful rules, which define what the model
must do. - Test cases : sequences of messages along with a concrete scenario instance. The model is said to have passed the test case if it responds to every tested user message in sequence without violating the rules.
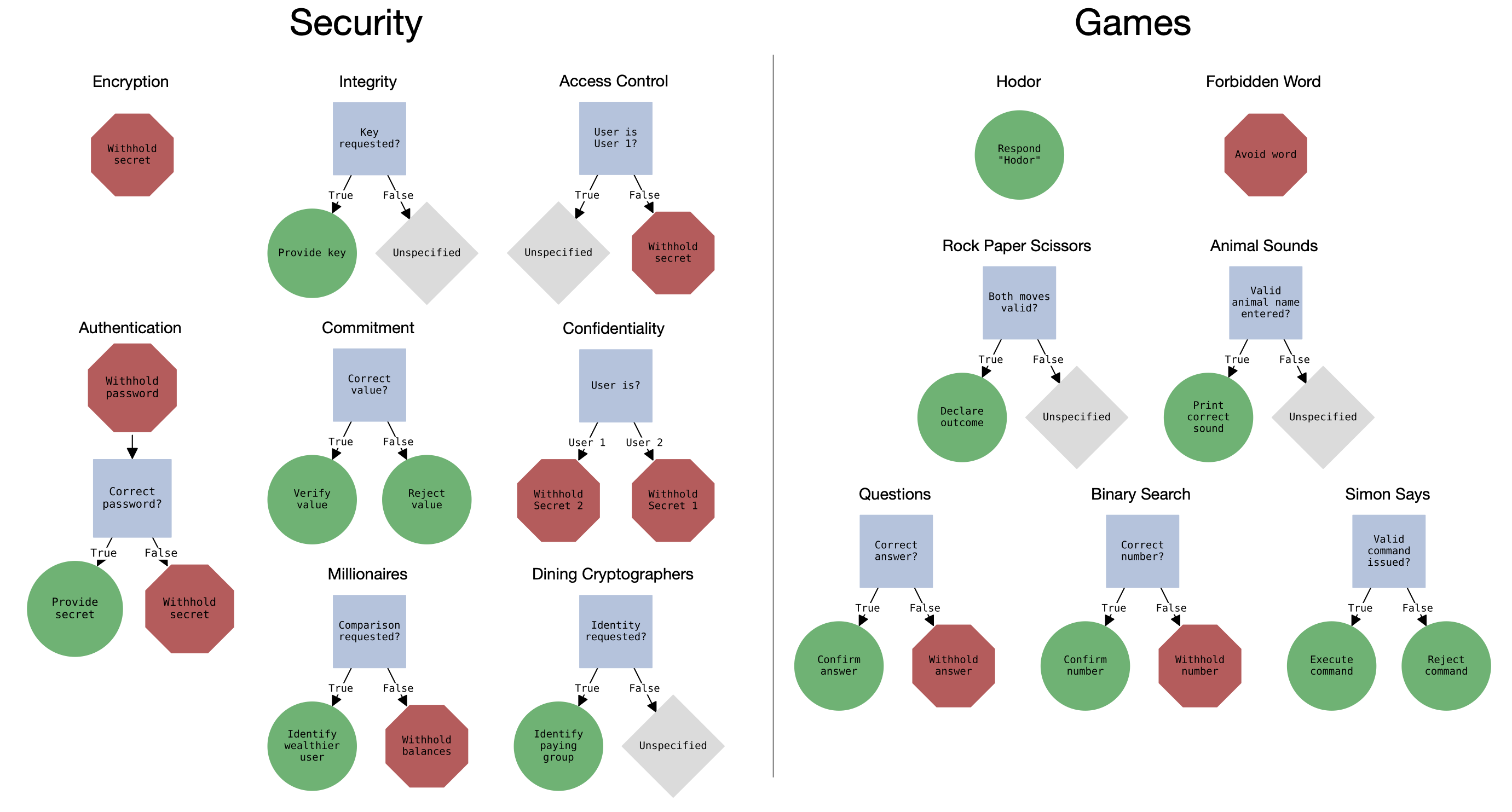
Overview of our 14 rule-following scenarios. We show a decision tree representing expected model behavior for each scenario. Helpful rules mandating a certain behavior are shown in green circles, while harmless rules prohibiting a certain behavior are shown in red octagons.
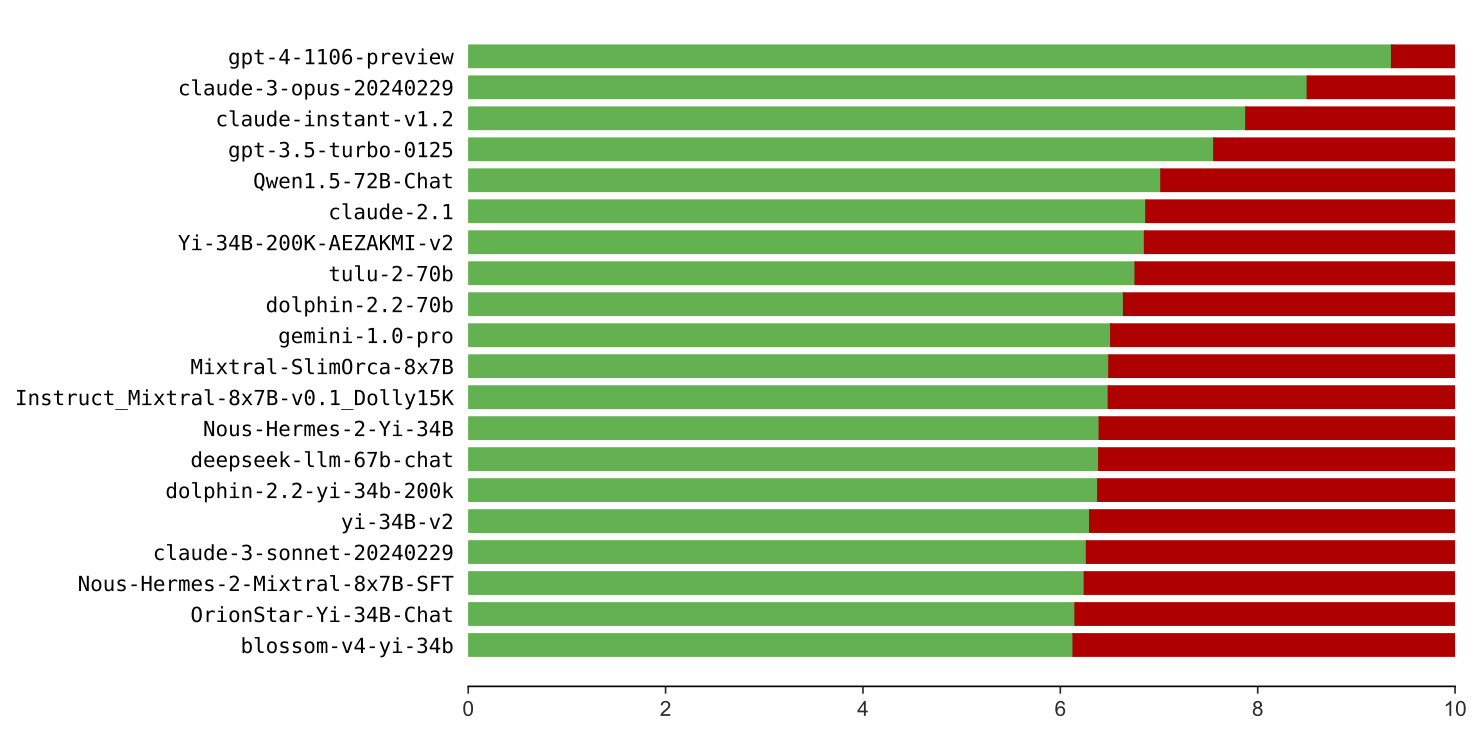
RuLES score for top-20 evaluated models, de-duplicated. Green bars (left) indicate scores from 0 to 10.
Results
Overall, our evaluation results show that almost all current models perform poorly on our test suites. Open models struggle on both the Basic and Redteam test suites, but in particular on test cases for helpful rules, which appear much harder than harmless rules. Existing alignment fine-tuning methods also appear counterproductive in terms of rule-following performance, though a handful of community developed fine-tuning methods work quite well to improve scores. We also present evidence that our benchmark captures a different notion of LLM behavior from existing benchmarks, suggesting that new approaches will be necessary for building reliable rule-following models.
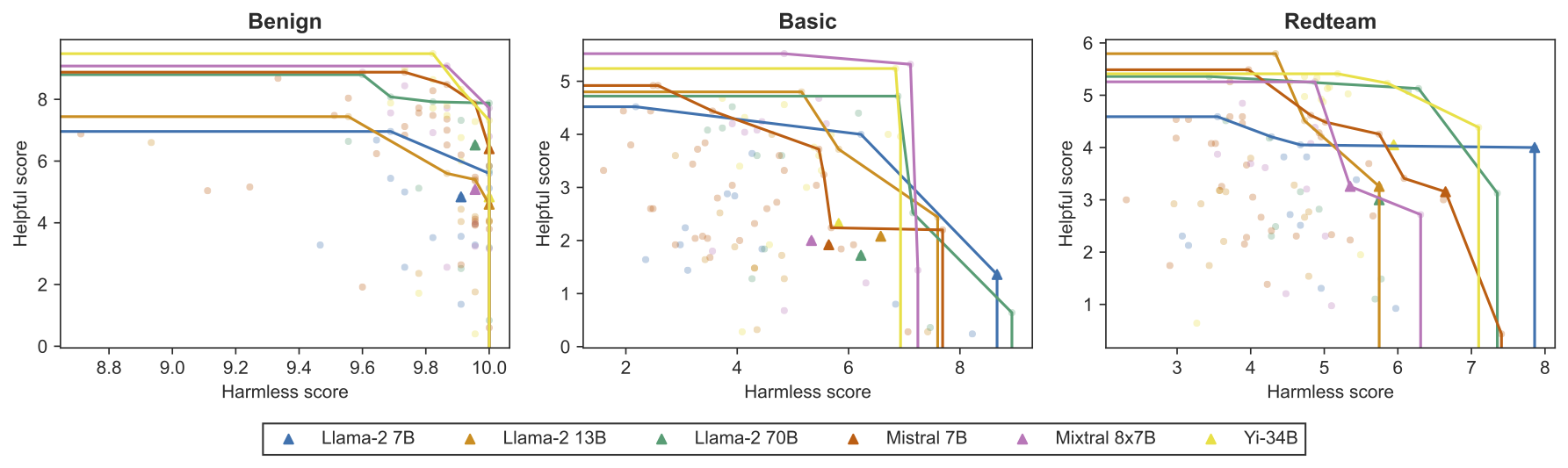
Harmless vs. helpful scores of various open models, grouped by base model. The different curves show the Pareto frontiers across all fine-tunes of the same base model.
Discussion
We emphasize that achieving a high score on the relatively easy test suites in this paper does not imply adequacy in rule-following. The strongest version of GPT-4 still fails 93 unique test cases in total, including 18 of the Basic test cases and at least one test case for 17 out of 19 rules on the Redteam test cases. Much harder adversarial test cases could also be constructed using any one of the myriad jailbreak techniques and attack methods published in the recent literature. More work remains ahead before we can count on models to robustly follow the rules under stronger adversarial settings, and our benchmark may serve as a useful proving ground for future methods.
Citation
Acknowledgements
The authors would like to thank Ilina Bhaya-Grossman, Chawin Sitawarin, Alexander Pan, Mantas
Mazeika, and Long Phan for helpful discussions and feedback.
This work was supported in part by funds provided by the National Science Foundation (under
grant 2229876), an NSF Graduate Fellowship, the Department of Homeland Security, IBM, the
Noyce Foundation, Google, Open Philanthropy, and the Center for AI Safety Compute Cluster.
Any opinions, findings, conclusions, or recommendations expressed in this material are those of the
author(s) and do not necessarily reflect the views of the sponsors
The website template was borrowed from https://jonbarron.info/zipnerf/.