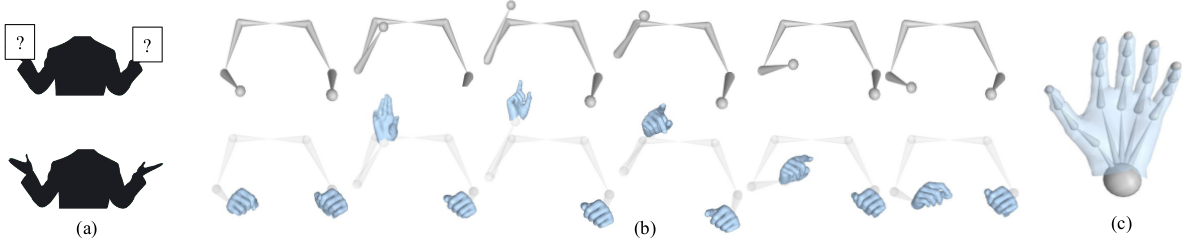
(3) Our method outperforms current SoTA in hand pose estimation, overcoming challenging views
While current image-based SoTA methods often fail on obstructed views of the hands, our prior based on body motion provides an additional cue for hand pose estimation to overcome challenges caused by fundamental depth ambiguity, frequent self-occlusion, and severe motion blur. Furthermore, we consider the temporal aspect of the input, allowing our method to produce smoother, more realistic hand sequences.

Our predicted 3D hand poses against a SOTA image-based method, MTC [Xiang et.al. ICCV 2019]. We show each prediction from a novel view below their respective hand. Row 1: View of speaker and magnified hands (not used by our method). Row 2: results from our method, using body-only as input. Row 3:MTC [Xiang et.al. ICCV 2019] image-based results. We show results from a person not seen in the training set (right) to demonstrate our model generalizes across individuals.
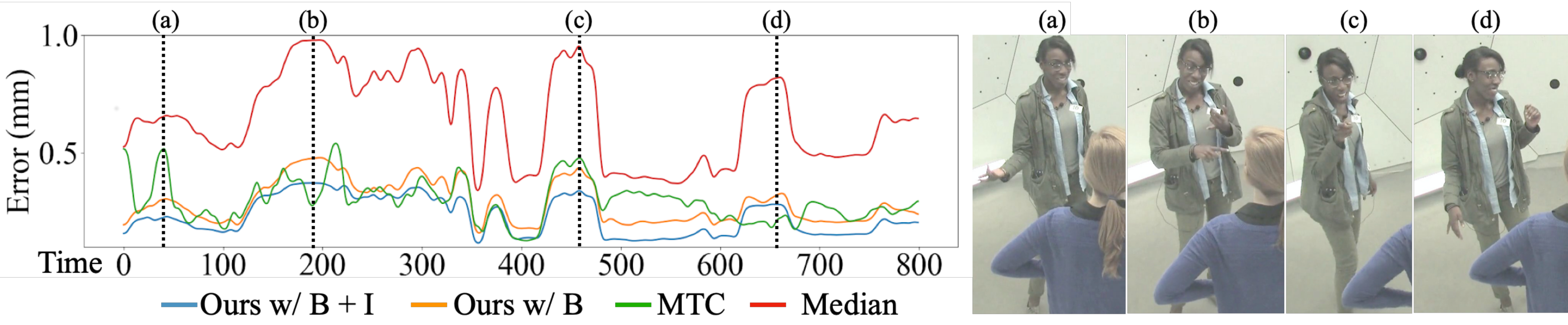
Analysis of typical errors. Error over time plotted on the left (lower is better). Frames shown for notable scenarios on the right. MTC fails from (a) naturally arising occlusions or from (c) motion blur/low resolution on hands. With clear views of the hands (b) and (d), MTC performs slightly better, though the margin separating ours from MTC is smaller than in cases where MTC fails. Overall, ours outperforms other baselines whether we take as input an image observation or not.