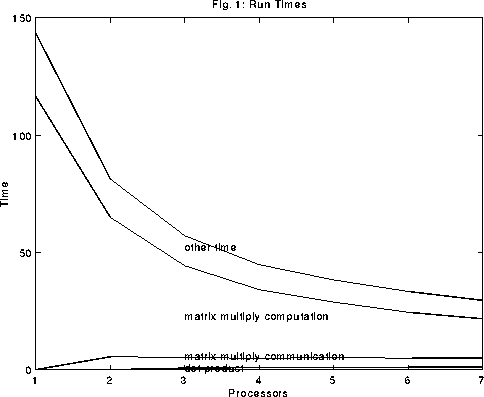
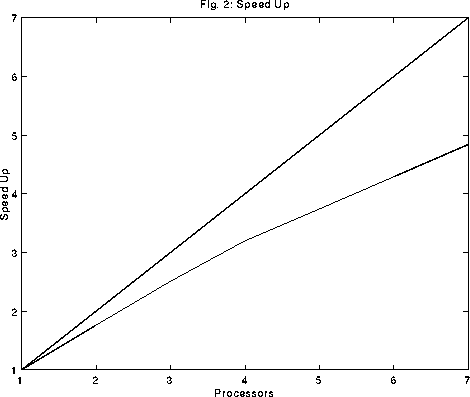
This project discussed some of the issues involved in parallelize a PCG solver in an FEM program. PCG solvers are ideal for large problems and parallel computing is also ideal for large problems - and will, in the future, be the most cost effective way of analyzing structures with large computational models (e.g. reasonably fine discritizations of large structures).
Future areas if research, that need to be addressed are improve the performance of the PCG algorithm on serial machines. There are many aspects of structural stiffness matrices which can be exploited, to improve performance, some of which have been implemented in this project.
Stiffness matrices are assembled in blocks, the blocks corresponding to unconstrained nodes are of size ndof by ndof, ndof being the number of degrees of freedom per node (i.e. ndof .eq. 3, for a 3D finite element analysis without temperature or rotational degrees of freedom). A common optimization in the implementation of high performance basic linear algebra subroutines (BLAS), for computers with cache memory, is to block matrices out into sub-matrices and carry out the algorithm (e.g a matrix-matrix multiply) on these sub-matrices. These sub-matrix operations can then be unrolled to attain high performance. This project has implemented such a blocking technique, for the matrix-vector multiply in the PCG algorithm, and the matrix-matrix multiply in the serial sparse Cholesky direct solver. Significant improvement in the run times for the direct solver on large problems has been observed, and the matrix-vector multiply on the SP1 runs at 13.5 Mflops (only multiplies are counted as flops). An additional advantage of this block type of data structure, which is basically a four dimensional array representation of the two dimensional stiffness matrix, is that all of the symbolic work need only be done for one of ndof**2 scalars in the stiffness matrix. This result in only having to store one index for each nine scalars (in the 3D case) in the sparse storage scheme, and more importantly only having to make one index dereference to get nine scalars at run time. This also means that the symbolic factorization (i.e. calculating the locations of the required fill in the sparse Cholesky factorization) need only be done on this reduced symbolic data.
Another area in which the nature of the structural stiffness matrix can be exploited is in the construction of the preconditions in the PCG algorithm. The PCG algorithm, with simple diagonal preconditioning, is extremely effective for well conditioned problems - unfortunately (or fortunately if you are a researcher), the number of iteration requires to get reasonable accuracy on typical structures is much lager than that required for very well conditioned matrices. I believe there are some properties of the stiffness matrix, that derive form the way that it is constructed and from what it physically represents, which can be profitably exploited to dramatically decrease the time required for convergence of the PCG algorithm. But, this is a topic of future research.