The matrix and vectors are layed out in a simple block column fashion.
The nodes are ordered in a natural order to minimize bandwidth
and hence interprocessor communication. The columns (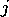 ) of the upper
triangular portion of the symmetric matrix
) of the upper
triangular portion of the symmetric matrix 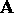 are layed out in
blocks on the processors, the vector members (
are layed out in
blocks on the processors, the vector members (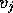 ) associated with the
columns of the matrix are put on the same processor. The matrix-vector
multiply
) associated with the
columns of the matrix are put on the same processor. The matrix-vector
multiply 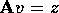 requires that the members of
the left hand side vector
requires that the members of
the left hand side vector 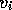 , which are in the same row as
an array member
, which are in the same row as
an array member 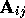 stored on another processor,
be communicated to carry out the
computation. The right hand side result
stored on another processor,
be communicated to carry out the
computation. The right hand side result 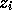 , then needs to be sent back
to the same processor that sent the left hand side (because of the
symmetry of ) - so that the final result can be calculated.
, then needs to be sent back
to the same processor that sent the left hand side (because of the
symmetry of ) - so that the final result can be calculated.