This project was implemented on an eight node, IBM SP1. This SP1 computing environment uses a Multiple Instruction Multiple Data (MIMD) computational model, though the current environment, of the SP1 here at Berkeley, seems to only support a slightly weaker model - the Single Program Multiple Data (SPMD). Thus, the entire program is loaded onto all of the participating processors, and conditionals are used to direct individual processors to do desired operations. Communication between processes is facilitated by libraries of communication subroutines - the IBM MPLp communication libraries. MPLp provides a system for arranging processors into groups which can then participate in collective communication library (CCL) calls, this type of routine is used for the dot product communication. MPLp also provides a wide assortment communication functions that can be used to send and receive data to and from explicitly identified processors, in a standard message passing style, these were used to communicate the vectors in the matrix-vector multiply.
The parallelization of a serial PCG solver within FEAP - required two basic types of parallel constructs. One, the coordination of the slave nodes in the different phases of the solver; and two, the communication and reduction operations used within the PCG algorithm.
The global coordination of the processors was implemented by having the program(s) first initialize there variables related to the computational environment (i.e. their taskid, the total number of processors, and various other useful variables). The main program, on the master processor, then executes FEAP proper - while the rest of the processors wait for messages from the master process:
program pfeap
call mp_environ(nproc, taskid)
c start node message loop
if ( taskid .neq. MASTER ) then
100 call mp_brecv(message,INTSIZE,MASTER,ND_ACTION,nbytes)
if ( message .eq. NODE_EXIT ) then
return
elseif ( message .eq. NODE_PCINIT ) then
call pc_init
elseif ( message .eq. NODE_SOLVINIT ) then
call init_solve
elseif ( message .eq. NODE_SOLVE ) then
call node_iter
else
stop ' ERROR: bad node loop message'
endif
goto 100
endif
... FEAP proper ...
c tell nodes to exit
do proci = 1, nproc-1
call mp_bsend(NODE_EXIT,INTSIZE,proci,ND_ACTION)
enddo
end
The master process (i.e. taskid .eq. 0)
would then also call the same subroutines, and
thus participate fully in the computation. Conditionals were
used to allow for any actions in which only the master processor
would execute (e.g. global output), and for actions which the
master processor would not participate (e.g. receiving a portion of the
matrix 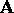 and right hand side
and right hand side 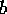 ).
A dot product is thus implemented as follows:
).
A dot product is thus implemented as follows:
temp = dot(z,r,local_neq)
call mp_combine(temp,d,REALSIZE,d_vadd,allgrp)