|
I am an assistant professor in computer science and engineering at the Paul G. Allen School at the University of Washington. Previously, I was a post-doctoral scholar at MIT, collaborating with Russ Tedrake and Pulkit Agarwal. I spent 6 wonderful years completing my PhD in machine learning and robotics at BAIR at UC Berkeley, where I was advised by Professor Sergey Levine and Professor Pieter Abbeel. In a previous life, I completed my bachelors degree also at UC Berkeley. My main research goal is to develop algorithms which enable robotic systems to learn how to perform complex tasks in a variety of unstructured environments like offices and homes. To that end, I work towards building deep reinforcement learning algorithms that can learn in the real world. Recently, I have been specifically focusing on the problems of reward specification, continual real world data collection and learning, offline reinforcement learning for robotics, multi-task and meta-learning and dexterous manipulation with robotic hands Email / CV / GitHub / Google Scholar / Ph.D. Thesis |

|
|
|
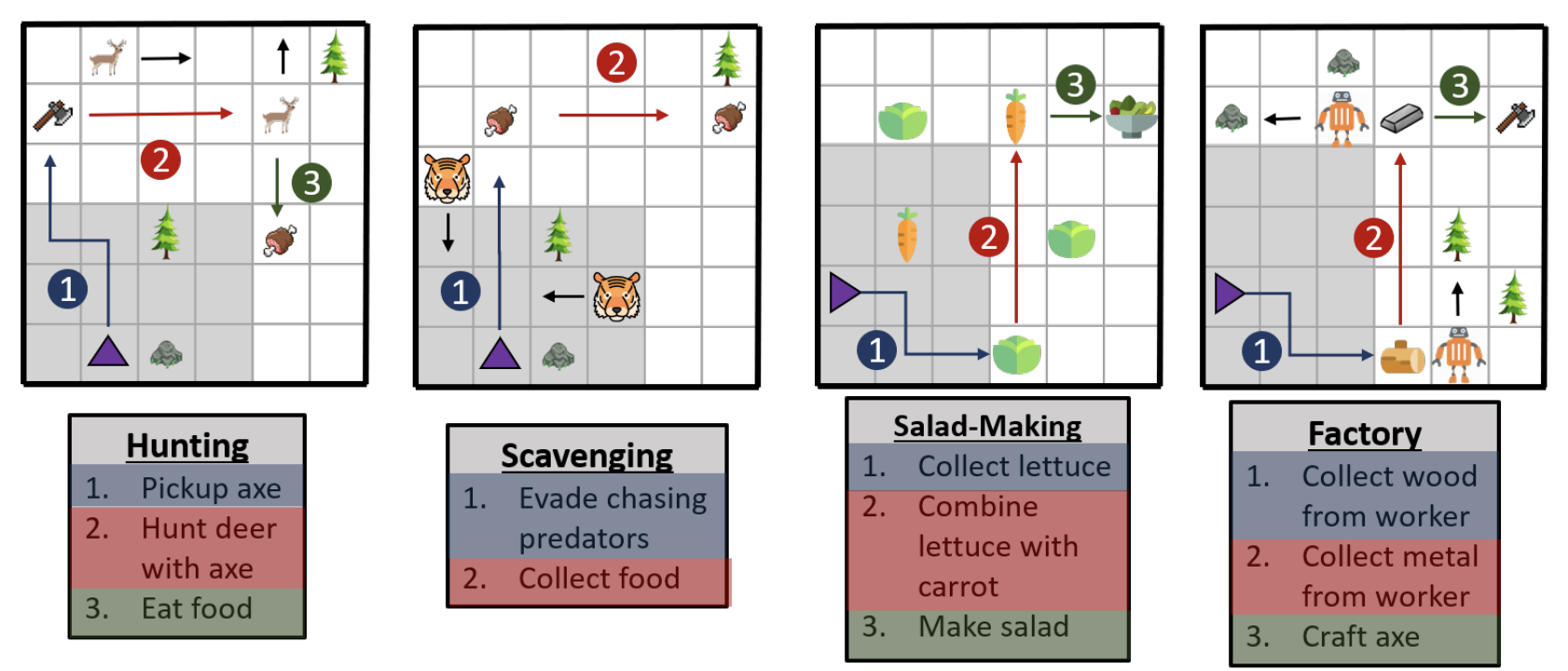
|
|
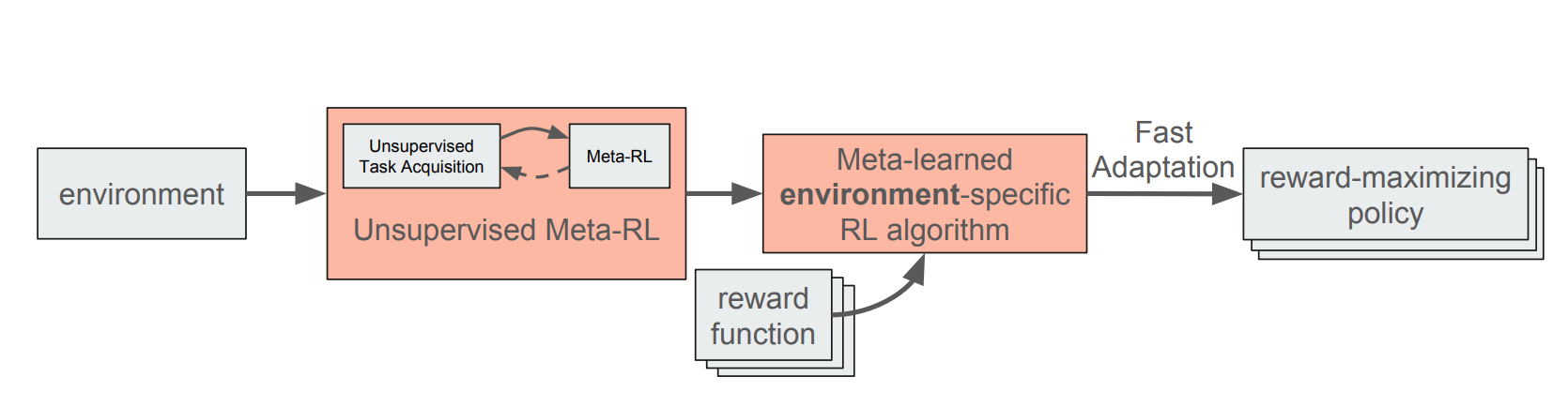
|
|
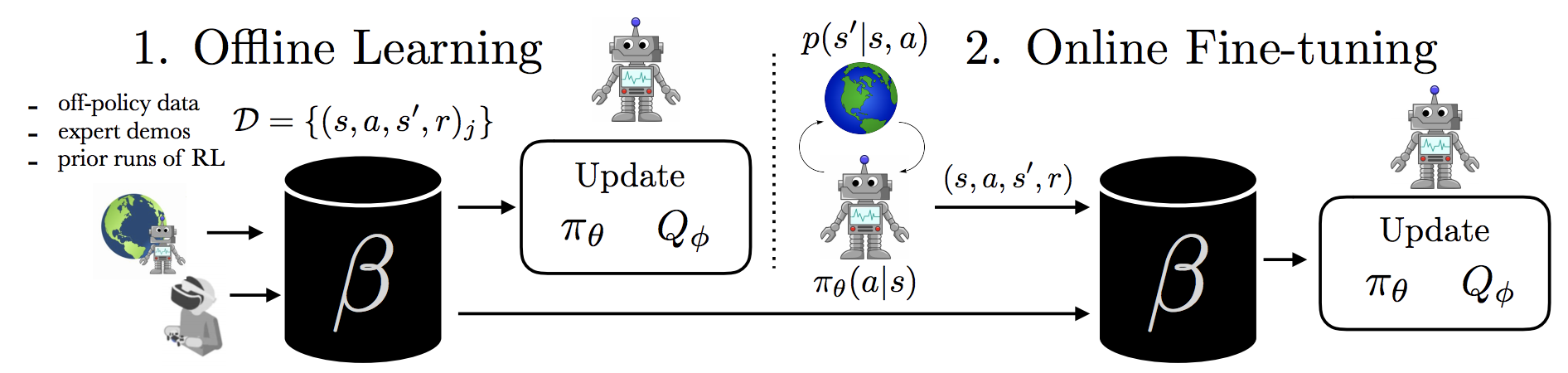
|
|
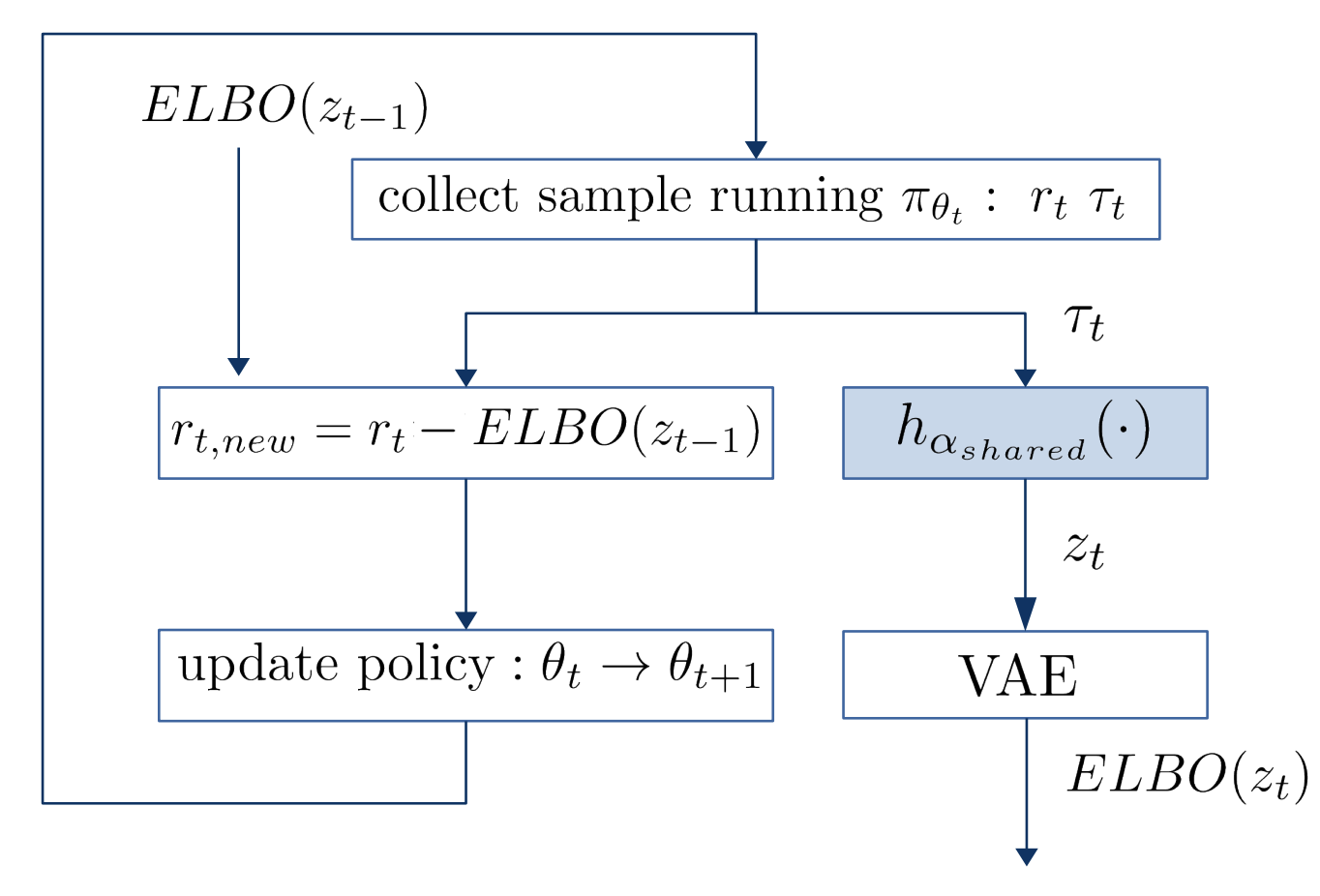
|
|
|
|
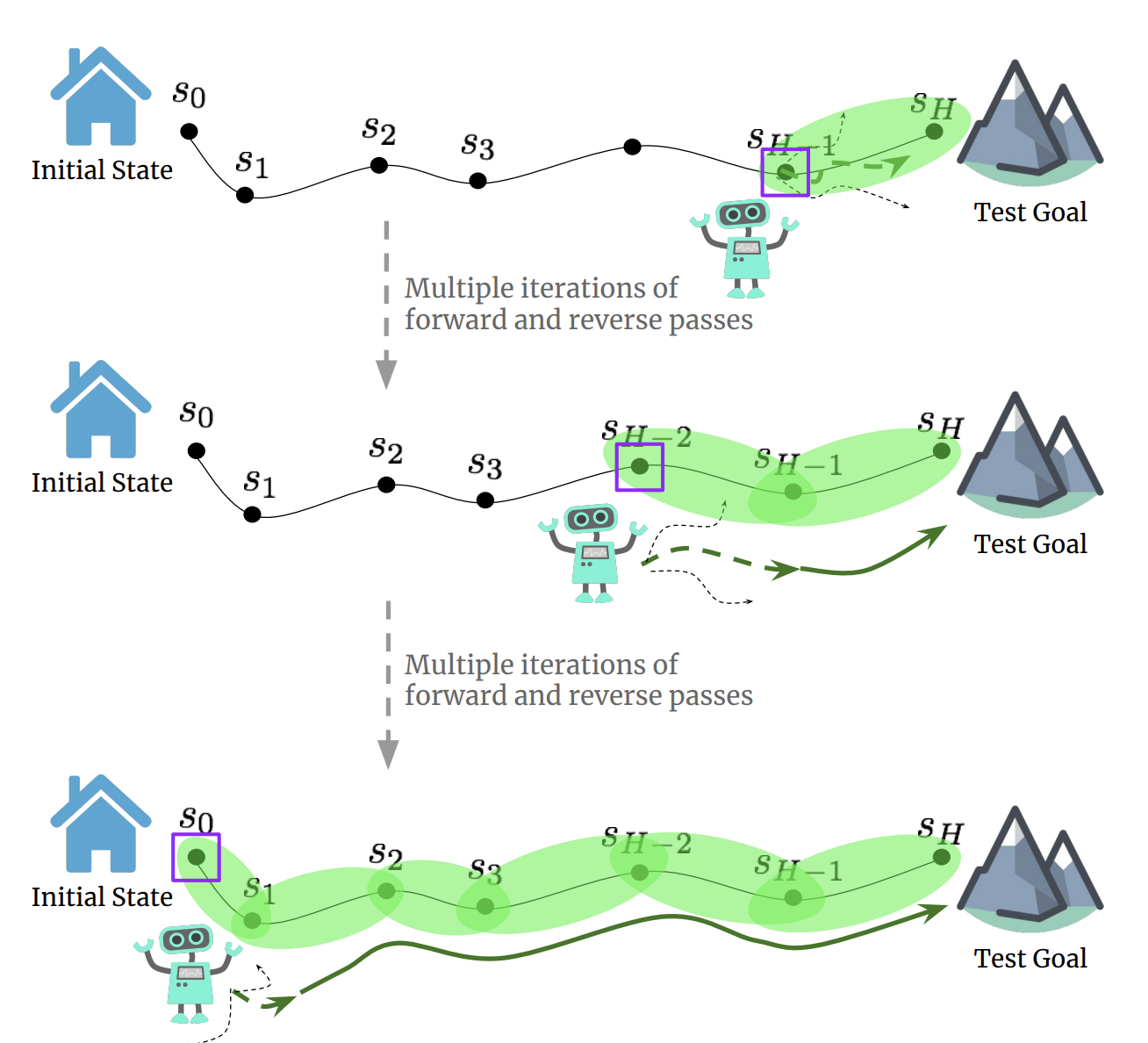
|
|
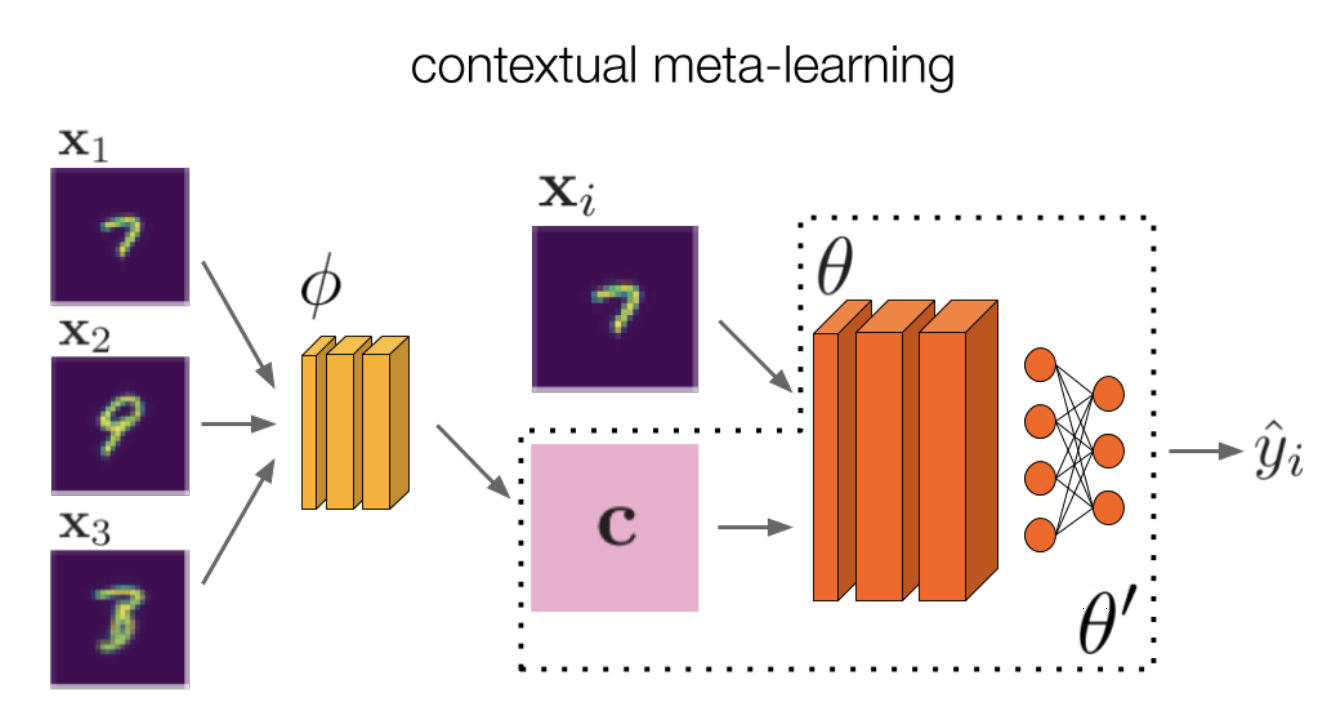
|
|
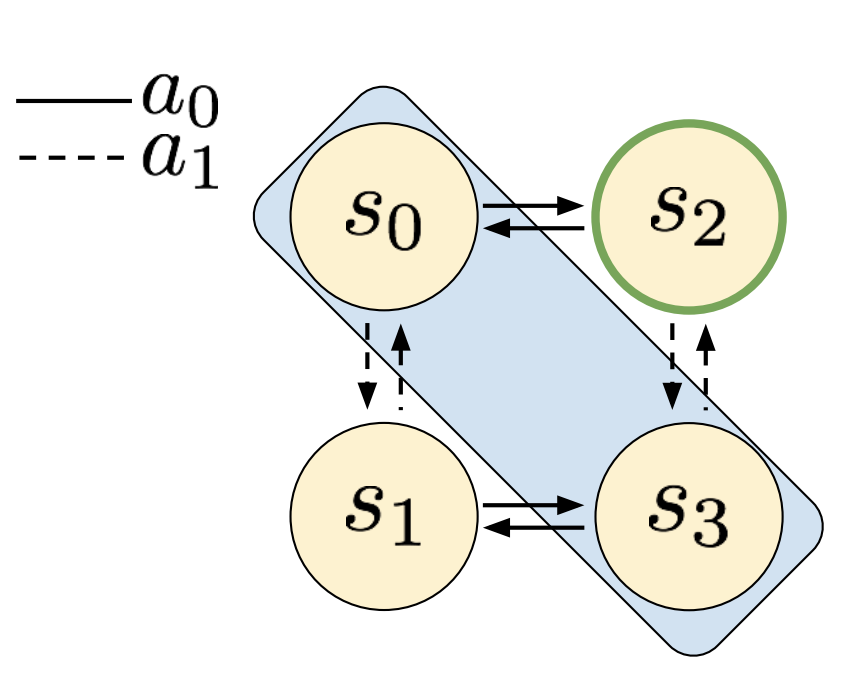
|
|

|
|
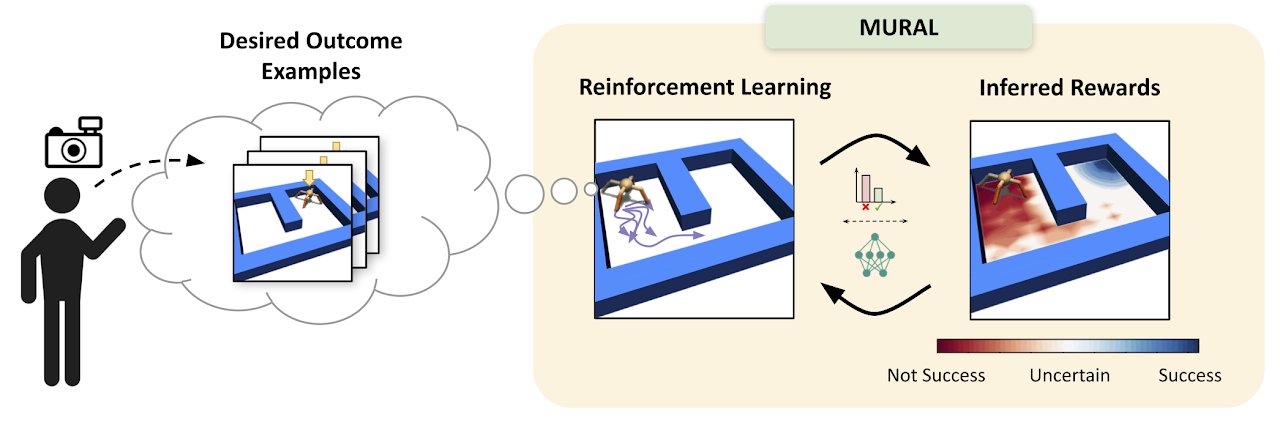
|
|

|
|

|
|

|
|
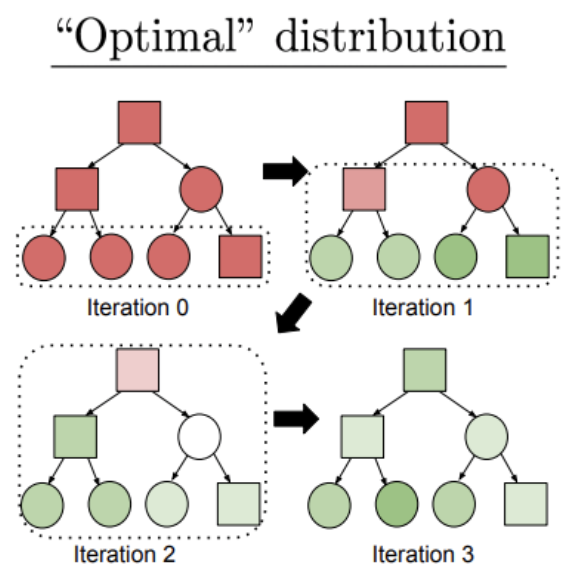
|
|
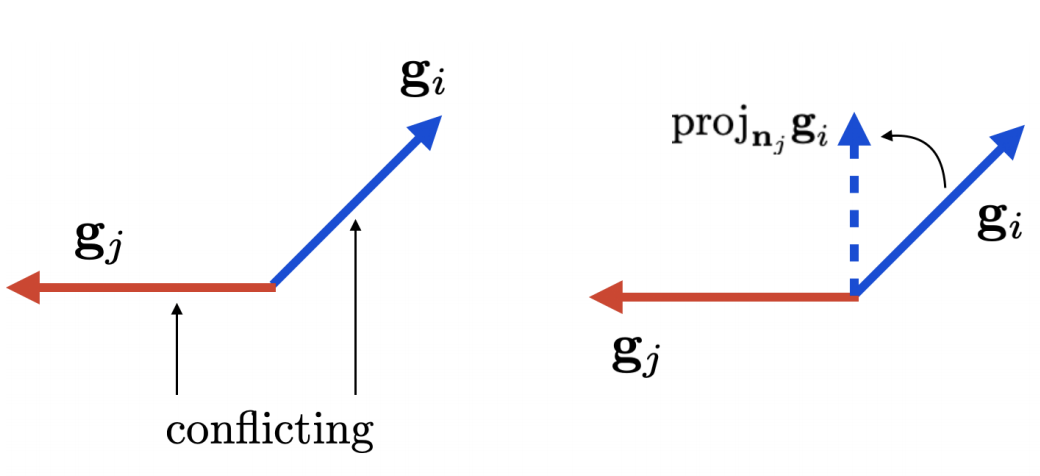
|
|
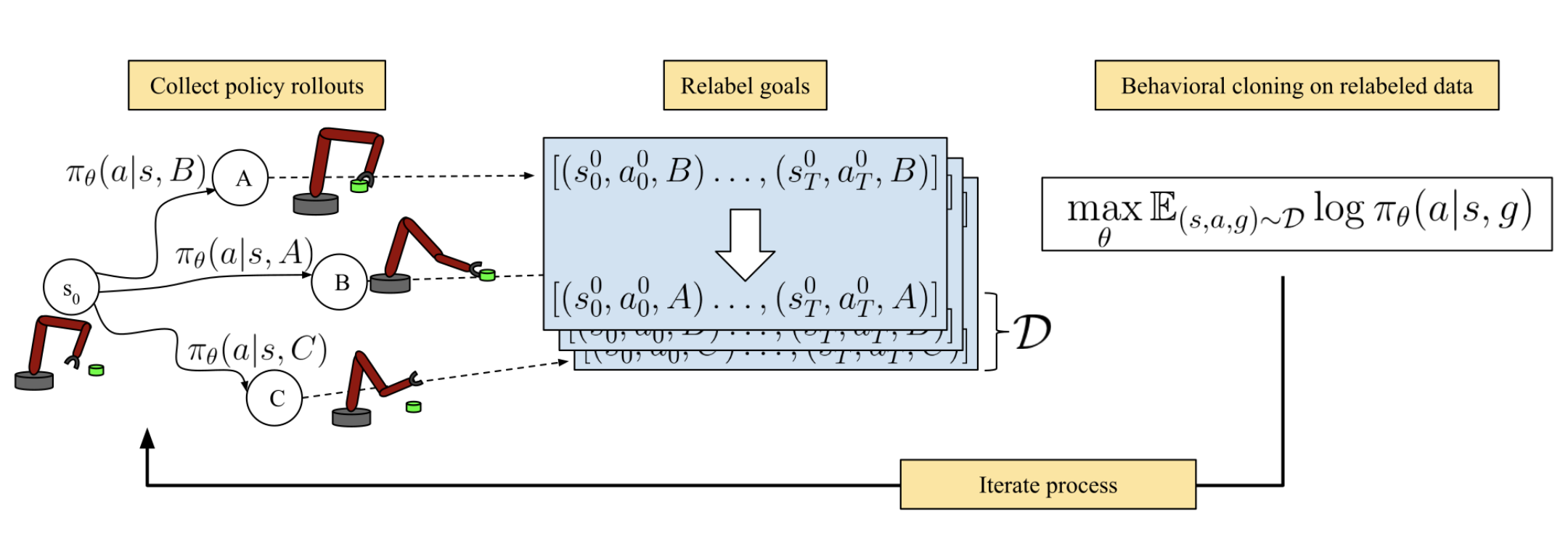
|
|

|
|

|
|
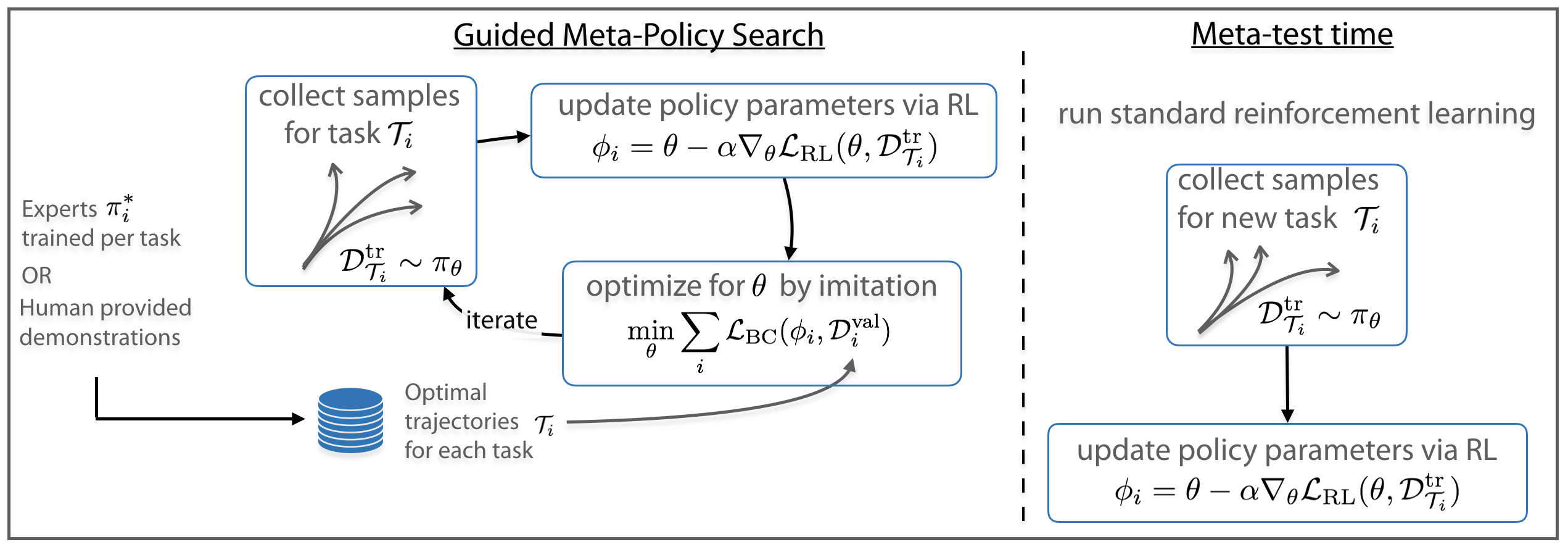
|
|

|
|
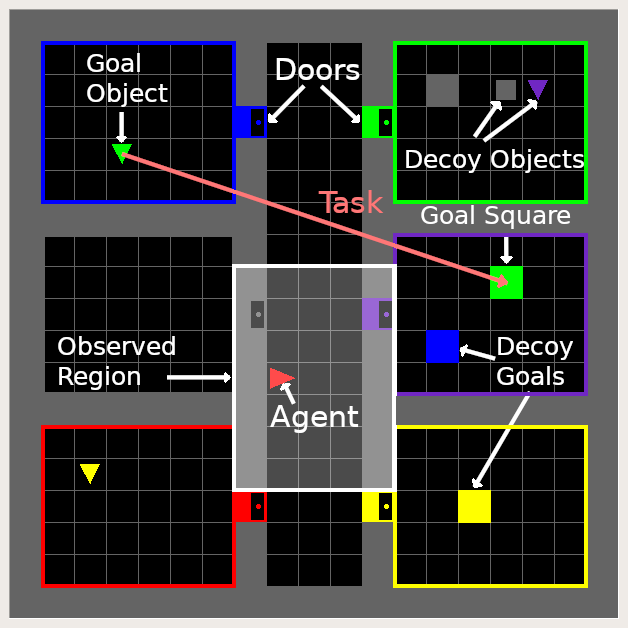
|
|

|
|

|
|
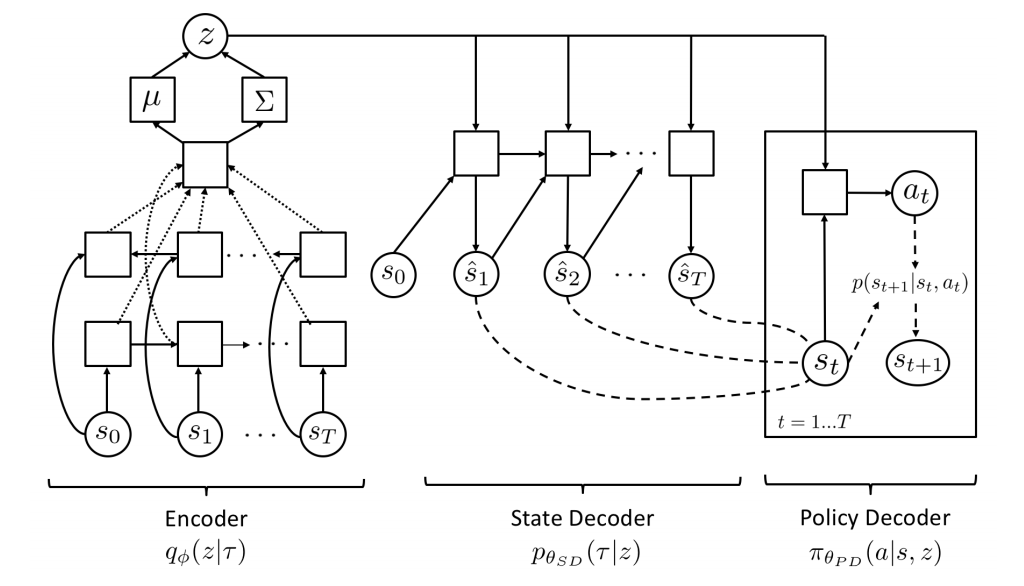
|
|
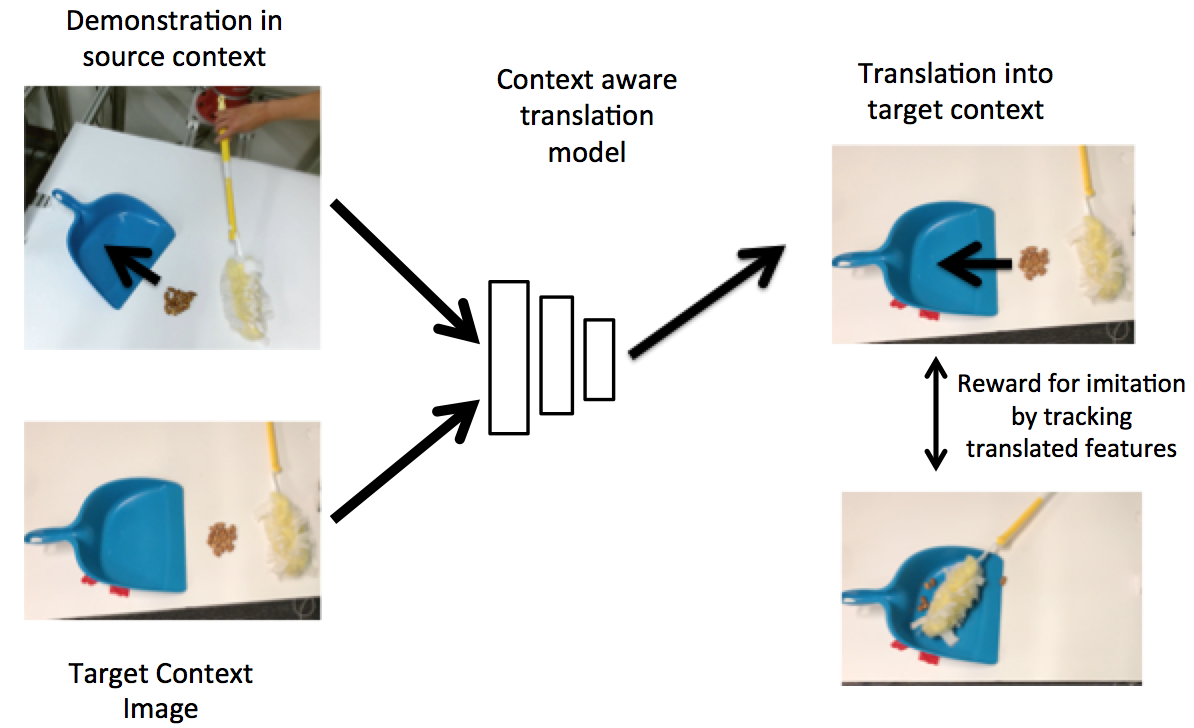
|
|
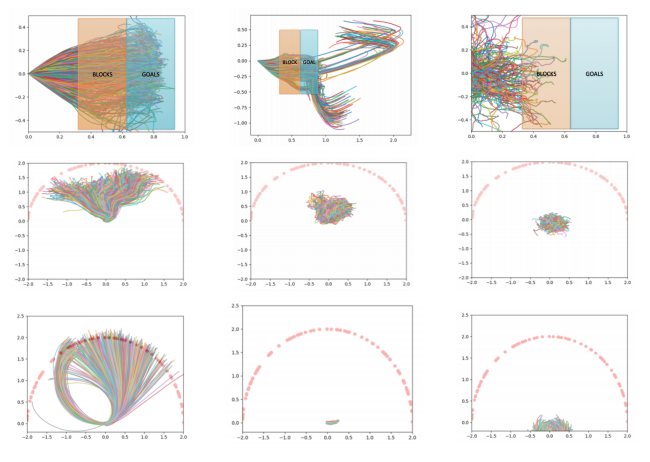
|
|

|
|

|
|
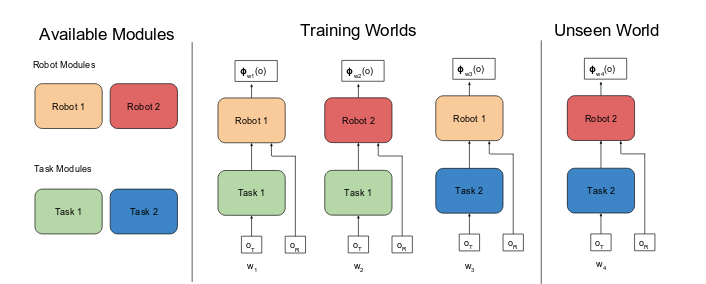
|
|
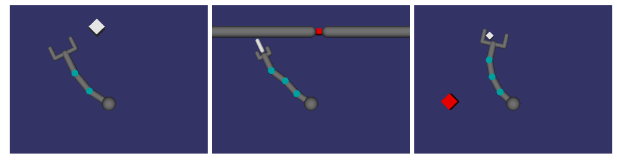
|
|

|
|

|
|

|
|

|
|

|
|
|
Website template from Jon Barron.
|