INTRODUCTION
This page provides a brief sketch of our new approach to the classification problem associated with face recognition. Given multiple training samples of each of k subjects, the problem is to classify a new test image as one of the k subjects. For simplicity, we shall consider the frontal face case, where face images have been properly cropped and normalized.
We assume that face images of the same person under varying illumination lie on a low-dimensional linear subspace. The individual subspaces can be represented by matrices A1, A2,...,Ak , where each column in Ai is a training sample from class i. Under this assumption, a test sample y from class j can be expressed as a linear combination of the columns of Aj . Therefore, if we let A = [ A1 A2 ... Ak ], then for some vector x that has non-zero components corresponding to the columns of Aj , we have y = Ax. Notice that the unknown x is a sparse vector, i.e., the number of non-zero components in x is much smaller than its dimension. Since the support of the sparse coefficients x reveals the identity of y, the original recognition problem can be solved by computing such a sparse representation.
Essentially, we now have a linear regression problem to solve. Typically, the columns of A are overcomplete (i.e., more columns than rows) and the solution to x is not unique. Conventionally, one seeks the least 2-norm solution for x, which is typically not the desired sparse solution. Recent results state that if the desired x is sparse enough, it can be recovered by minimizing the L1 norm. The theory behind this can be explained using the geometry of high-dimensional polytopes:
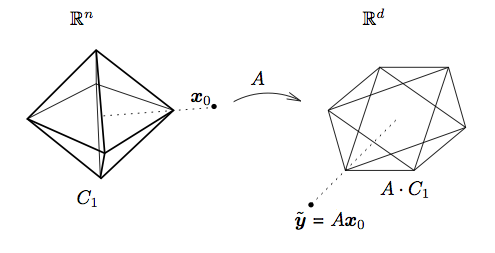
In the above figure, x0 is the desired sparse solution, C1 is the standard L1-ball or the cross-polytope in Rn. The matrix A essentially projects the cross-polytope into Rd, where d < n. The cross-polytope is expanded until a facet of the projected polytope touches the test sample y. Most matrices A preserve the low-dimensional faces of C1, mapping them to faces of the projected polytope. The sparse solutions x associated with these faces are correctly recovered by L1 minimization.
The theory of sparse reprersentation gives us a computationally tractable method to compute the sparse solution x. To classify y, we consider the contribution of coefficients of x associated with each subject towards the reconstruction of y, and classify y as the subject whose training samples best approximate the test sample. More precisely, the proposed face recognition algorithm can be summarised by the following pseudo-code:
We assume that face images of the same person under varying illumination lie on a low-dimensional linear subspace. The individual subspaces can be represented by matrices A1, A2,...,Ak , where each column in Ai is a training sample from class i. Under this assumption, a test sample y from class j can be expressed as a linear combination of the columns of Aj . Therefore, if we let A = [ A1 A2 ... Ak ], then for some vector x that has non-zero components corresponding to the columns of Aj , we have y = Ax. Notice that the unknown x is a sparse vector, i.e., the number of non-zero components in x is much smaller than its dimension. Since the support of the sparse coefficients x reveals the identity of y, the original recognition problem can be solved by computing such a sparse representation.
Essentially, we now have a linear regression problem to solve. Typically, the columns of A are overcomplete (i.e., more columns than rows) and the solution to x is not unique. Conventionally, one seeks the least 2-norm solution for x, which is typically not the desired sparse solution. Recent results state that if the desired x is sparse enough, it can be recovered by minimizing the L1 norm. The theory behind this can be explained using the geometry of high-dimensional polytopes:
In the above figure, x0 is the desired sparse solution, C1 is the standard L1-ball or the cross-polytope in Rn. The matrix A essentially projects the cross-polytope into Rd, where d < n. The cross-polytope is expanded until a facet of the projected polytope touches the test sample y. Most matrices A preserve the low-dimensional faces of C1, mapping them to faces of the projected polytope. The sparse solutions x associated with these faces are correctly recovered by L1 minimization.
The theory of sparse reprersentation gives us a computationally tractable method to compute the sparse solution x. To classify y, we consider the contribution of coefficients of x associated with each subject towards the reconstruction of y, and classify y as the subject whose training samples best approximate the test sample. More precisely, the proposed face recognition algorithm can be summarised by the following pseudo-code:
- Input: n training samples partitioned into k classes, A1, A2,...,Ak and a test sample y.
- Set A = [ A1 A2 ... Ak ].
- Use linear programming to solve the L1 minimization problem : min || x ||1 subject to y = Ax.
- Compute the residuals: ri = || y - Axi ||2, where xi is obtained by setting the coefficients in x, corresponding to training samples not in class i, to zero.
- Output: the class with the smallest residual.