ABSTRACT
-----
Convolution is the main building block of convolutional neural networks (CNN). We observe that an optimized CNN often has highly correlated filters as the number of channels increases with depth, reducing the expressive power of feature representations. We propose Tied Block Convolution (TBC) that shares the same thinner filters over equal blocks of channels and produces multiple responses with a single filter. The concept of TBC can also be extended to group convolution and fully connected layers, and can be applied to various backbone networks and attention modules.
Our extensive experimentation on classification, detection, instance segmentation, and attention demonstrates TBC’s significant across-the-board
gain over standard convolution and group convolution. The proposed TiedSE attention module can even use 64
METHOD
-----
Method overview
To generate two activation maps, standard convolution requires two full-size filters and group convolution requires two half-size filters,
however, our tied block convolution only requires one half-size filter, that is, the parameters are reduced by 4
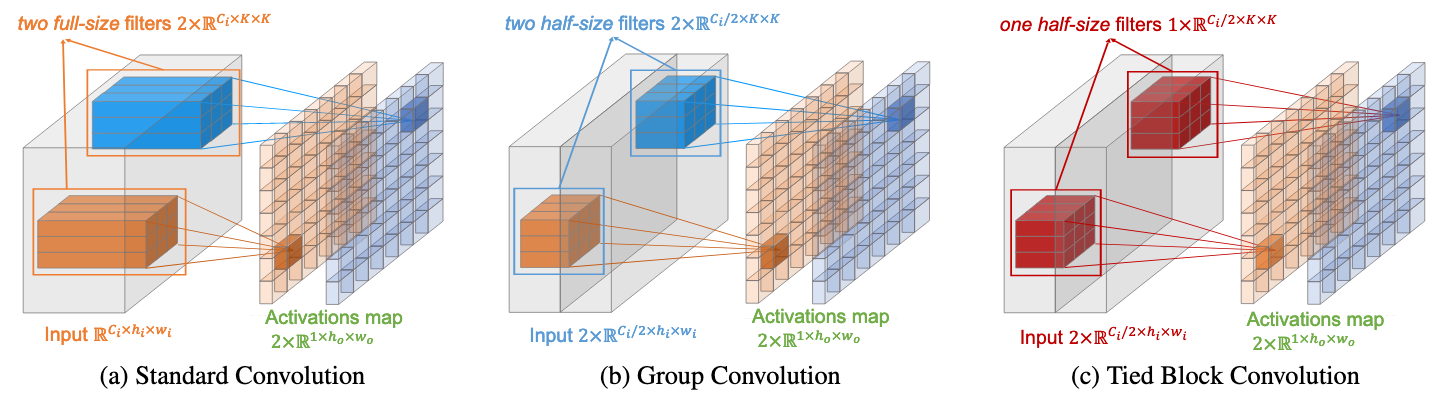
Fig 1. Standard Conv vs. Group Conv vs. Tied Block Conv
Standard Convolution
Let the input feature be denoted by
where
Group Convolution
Group Convolution first divides input feature
where
Tied Block Convolution (TBC)
Tied Block Convolution reduces the effective number of filters by reusing filters across different feature groups with the following formula:
where
Tied Block Group Convolution (TGC)
The idea of tied block filtering can also be directly applied to group convolution, formulated as:
where
Tied Block Fully Connected Layer (TFC)
Convolution is a special case of fully connected (FC) layer, just as FC is a special case of convolution. We apply the same tied block filtering idea to FC.
Tied block fully connected layer (TFC) shares the FC connections between equal blocks of input channels.
Like TBC, TFC could reduce
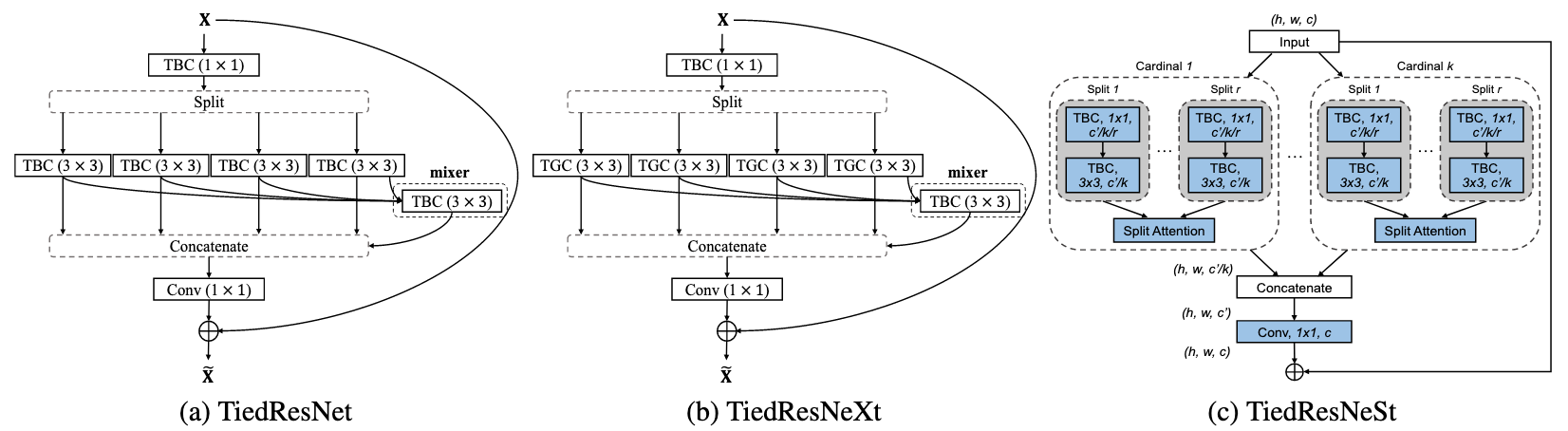
Fig 2. Diagram of bottleneck modules for (a) TiedResNet with 4 splits (b) TiedResNeXt with 4 splits and (c) TiedResNeSt. Each tied block convolution (TBC) and tied block group convolution (TGC) has a specific block number.
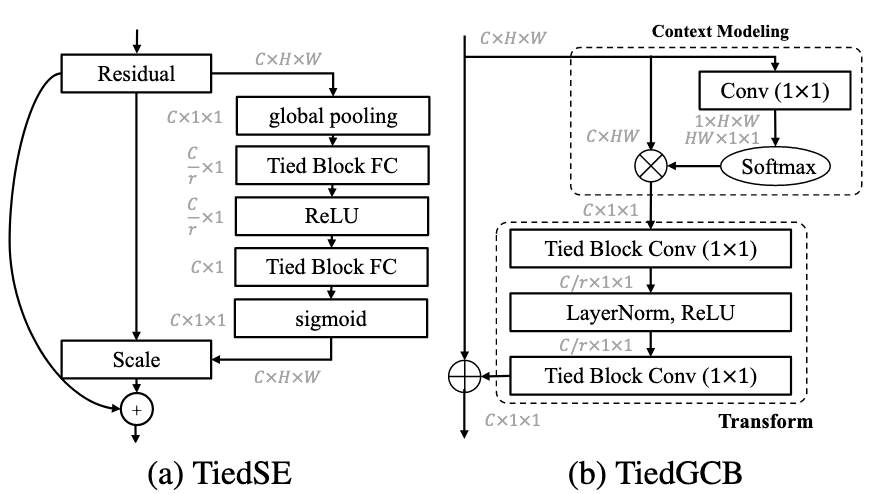
Fig 3. Diagram of Tied attention modules. (a) TiedSEmodule replaces FC in the original squeeze-and-excitation (SE) module to be TFC. (b) TiedGCB module replaces standard convolution in global context block (GCB) with TBC.
Results
-----
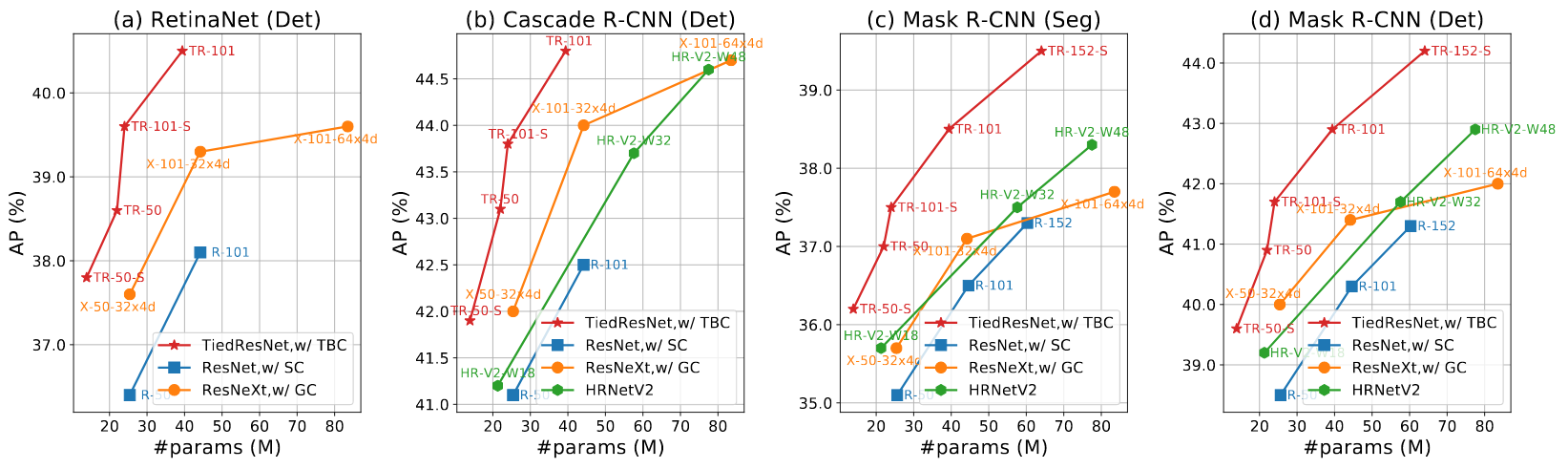
Fig 4. #params of backbones vs. their Average Precision on object detection and instance segmentation tasks of MS-COCO val-2017.

Fig 5. We evaluate TiedResNet and ResNet performance on object detection task of MS-COCO with different occlusion ratio
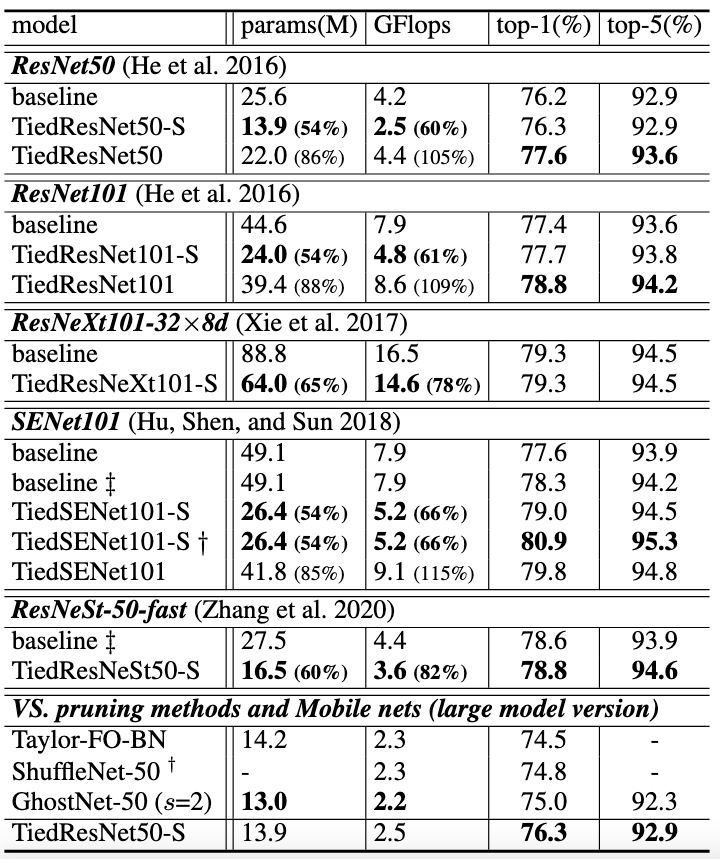
Fig 6. Recognition accuracy and model size comparison on ImageNet-1k.

Fig 7. Comparison on instance segmentation task of Cityscapes val set.
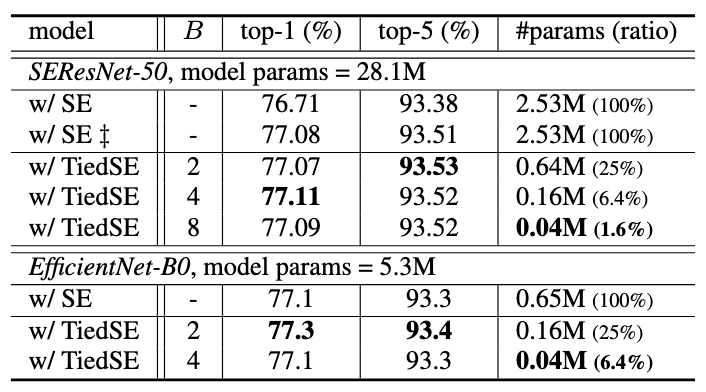
Fig 8. Comparison on #params of attention module SE/TiedSE with various backbones.
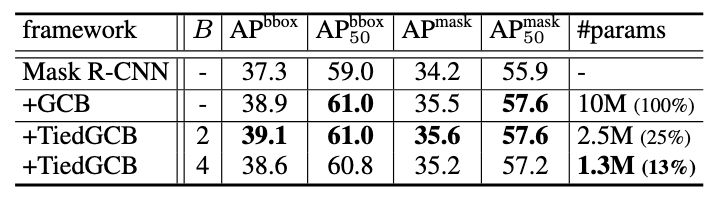
Fig 9. Comparison on #params of attention module GCB/TiedGCB.

Fig 10. Additional Grad-CAM visualization comparison among ResNet50, ResNeXt50 and TiedRes-Net50 in Rows 2-4 respectively for images in Row 1.
-----
PUBLICATION
-----
Tied Block Convolution: Leaner and Better CNNs with Shared Thinner Filters
Xudong Wang and Stella X. Yu
The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI), 2021.
CITATION
-----
@article{wang2020unsupervised,
title={Tied Block Convolution: Leaner and Better CNNs with Shared Thinner Filters},
author={Wang, Xudong and Yu, Stella X},
journal={arXiv preprint arXiv:2009.12021},
year={2020}
}