Learning Individual Styles of Conversational Gesture
UC Berkeley
Zebra Medical
MIT
CVPR 2019

Abstract
Human speech is often accompanied by hand and arm gestures. Given audio speech input, we generate plausible gestures to go along with the sound. Specifically, we perform cross-modal translation from "in-the-wild" monologue speech of a single speaker to their hand and arm motion. We train on unlabeled videos for which we only have noisy pseudo ground truth from an automatic pose detection system. Our proposed model significantly outperforms baseline methods in a quantitative comparison. To support research toward obtaining a computational understanding of the relationship between gesture and speech, we release a large video dataset of person-specific gestures.
Paper
-

Learning Individual Styles of Conversational Gesture
Shiry Ginosar*, Amir Bar*, Gefen Kohavi, Caroline Chan, Andrew Owens and Jitendra Malik Learning Individual Styles of Conversational Gesture, Computer Vision and Pattern Recognition, CVPR 2019.
PDF, BibTeX@InProceedings{ginosar2019gestures,
author={S. Ginosar and A. Bar and G. Kohavi and C. Chan and A. Owens and J. Malik},
title = {Learning Individual Styles of Conversational Gesture},
booktitle = {Computer Vision and Pattern Recognition (CVPR)}
publisher = {IEEE},
year={2019},
month=jun
}
Demo
Code
[Tensorflow]
Data
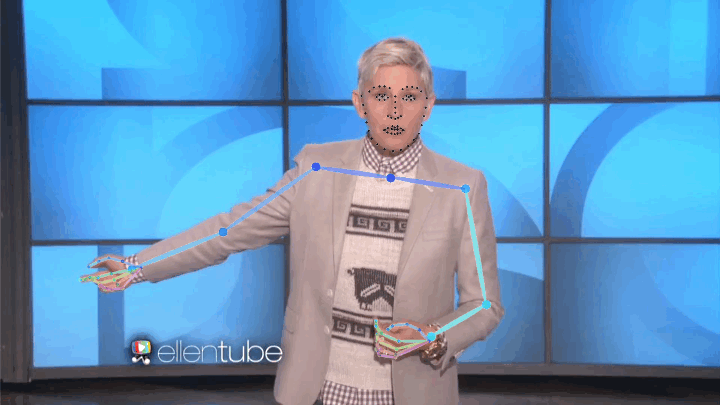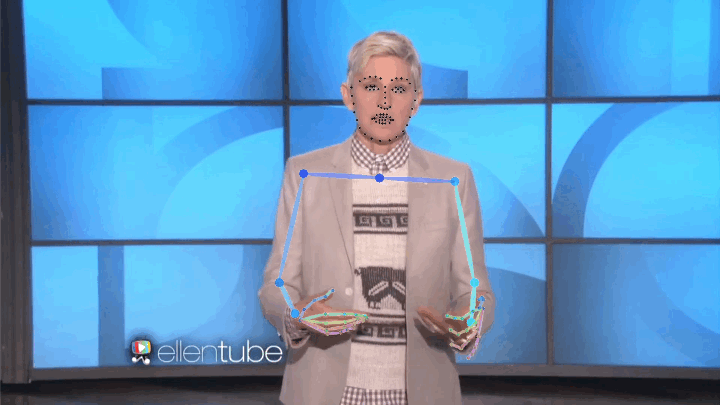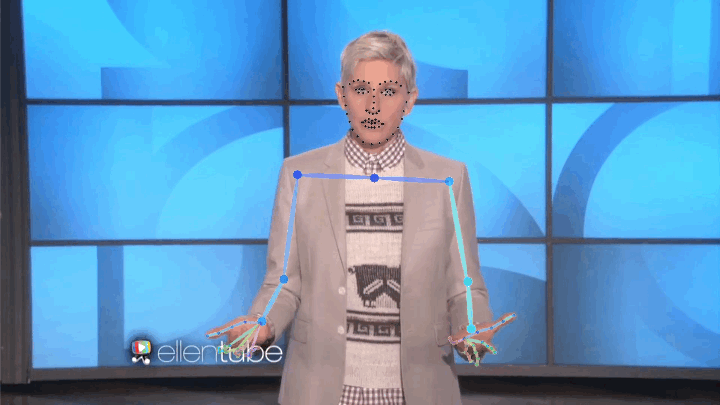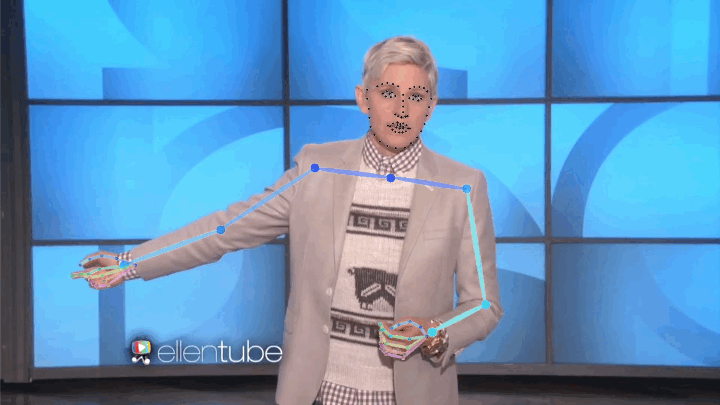




We present a large, 144-hour person-specific video dataset of 10 speakers, with frame-by-frame automatically-detected pose annotations. We deliberately pick a set of speakers for which we can find hours of clean single-speaker footage. Our speakers come from a diverse set of backgrounds: television show hosts, university lecturers and televangelists. They span at least three religions and discuss a large range of topics from commentary on current affairs through the philosophy of death, chemistry and the history of rock music, to readings in the Bible and the Qur'an.
Note: the data for Conan was updated recently to remove duplicate videos. The numerical results pertaining to Conan will be updated soon.
Press Coverage

Acknowledgements
This work was supported, in part, by the AWS Cloud Credits for Research and the DARPA MediFor programs, and the UC Berkeley Center for Long-Term Cybersecurity. Special thanks to Alyosha Efros, the bestest advisor, and to Tinghui Zhou for his dreams of late-night talk show stardom.