
News
• Helix, an LLM inference system for heterogeneous GPU clusters, accepted at ASPLOS 2025. Congratulations to Yixuan!
• Morph, file-lifetime redundancy management in cluster file systems, presented at SOSP 2024. Congratulations to Tim and Sanjith!
• Juncheng Yang accepts tenure track assistant professor offer from Harvard CS. Congratulations to Juncheng!
• Our paper on SIEVE, a novel eviction algorithm for web caches, wins USENIX NSDI 2024 Community (Best Paper) Award! Congratulations to Yazhuo and Juncheng!
• S3-FIFO (ACM SOSP 2023), our new cache eviction algorithm, has been adopted at VMware, Google, Redpanda, and several opensource libraries and systems!
• S3-FIFO (ACM SOSP 2023) reached top of HackerNews!
• Honored to be named Sloan Research Fellow 2023.
• Honored to be named IEEE Information Theory Society Goldsmith Lecturer 2023.
• Honored to receive Meta SDCs at scale Research Award 2022.
• Our paper on Pacemaker (USENIX OSDI 2020) chosen among Highlight Papers at ACM Systor 2022.
• Honored to receive 2021 VMware Systems Research Award.
• Our paper on Segcache, a memory-efficient and high-throughput in-memory cache, wins USENIX NSDI 2021 Community (Best Paper) Award! Congratulations to Juncheng!
• "FoldedCNNs", a novel approach for high throughput, high GPU-utilization specialized CNN inference, accepted to ICML 2021. Congratulations to Jack!
• Invited talk at Stanford Compression Workshop 2021.
• "Segcache", a memory-efficient and high-throughput in-memory cache, accepted to NSDI 2021. Congratulations to Juncheng!
• Our OSDI 2020 paper recognized by the PC chairs as one of the best storage-related papers of OSDI 2020 and invited to the ACM Transactions on Storage. Congratulations to Juncheng!
• Saurabh successfully defended his Ph.D. thesis! Congratulations to Saurabh!
• Two papers from our group accepted for publication at OSDI 2020 (on resource efficiency in storage and in-memory caching systems). Congratulations to Jason, Saurabh, Francisco and Suhas!
• Excited to be participating in the live panel sesssion on Machine-learning based approaches to coding" at IEEE ISIT 2020.
• Honored to receive NSF CAREER Award 2020.
• Honored to receive Facebook Distributed Systems Research Award 2019.
• Juncheng Yang receives Facebook PhD fellowship. Congratulations, Juncheng!
• Honored to receive "Prof. Narasimhan Memorial Lecture Award 2020" from Tata Institute of Fundamental Research.
• Our work on a new class of storage codes called Convertible codes to appear in ITCS (Innovations in Theoretical Computer Science) 2020.
• Invited talk at AISystems workshop at ACM SOSP 2019.
• Our work on learning-based coded computation for ML inference systems to appear in ACM SOSP 2019.
• Invited talk at Facebook Networking and Communications Faculty Summit 2019.
• Invited talk at ICML 2019 CodML Workshop on "Reslient ML Inference via Coded Computation: A learning-based Approach" (video).
• Our work on social live video streaming to appear in ACM SIGCOMM 2019.
• Google Faculty Research Award 2018.
• NSF CRII 2018.
• Program committee member for USENIX NSDI 2020.
• Invited talk at ITA 2019.
• Invited attendee at Microsoft Systems Faculty Summit 2018.
• Program committee member for USENIX OSDI 2018.
• Program committee member for SysML 2018.
• Joined CMU CS as an assistant professor.
• Received Eli Jury Award 2016 for best thesis in the area of Systems, Communications, Control, or Signal Processing at EECS, UC Berkeley.
• Invited talk at ITA Graduation Day 2016.
• Invited talk at Allerton 2015.
• Awarded Google Anita Borg Memorial Scholarsihp 2015.
• 'Reducing I/O cost in distributed storage codes' at USENIX FAST 2015. Chosen as the best paper of USENIX FAST 2015 by StorageMojo.
I am an Associate Professor in the Computer Science Department at Carnegie Mellon University, where I am a part of both the Systems group and the Theory group. I lead the CMU TheSys research group, and also a part of the Parallel Data Lab (PDL). Before joining CMU, I did my Ph.D. and postdoctoral studies at UC Berkeley. My research interests broadly lie in computer/networked systems and information/coding theory, and the wide spectrum of intersection between the two areas.
My current focus is on robustness and resource efficiency in data systems spanning across the system stack including storage, communication, and computation. The key thrusts include storage systems, caching systems, and systems for machine learning.
The research from my group has been adopted by industry, both in large-scale production systems and in popular open source libraries, has been featured on popular media platforms, and has won multiple best paper awards. Check out our research below!
A note to prospective students:
Due to the high volume of emails that I receive from prospective students, unfortunately, I am unable to respond to them. Apologies in advance for this. But, I do catch up with these emails eventually, if there is a good fit and an opening in my group. If you are interested in joining my group as a PhD student, please apply to either CSD or ECE departments at CMU and write my name in your application.
My current focus is on robustness and resource efficiency in data systems spanning across the system stack including storage, communication, and computation. The key thrusts include storage systems, caching systems, and systems for machine learning.
The research from my group has been adopted by industry, both in large-scale production systems and in popular open source libraries, has been featured on popular media platforms, and has won multiple best paper awards. Check out our research below!
A note to prospective students:
Due to the high volume of emails that I receive from prospective students, unfortunately, I am unable to respond to them. Apologies in advance for this. But, I do catch up with these emails eventually, if there is a good fit and an opening in my group. If you are interested in joining my group as a PhD student, please apply to either CSD or ECE departments at CMU and write my name in your application.
TheSys ("Theory + Systems") Group
Overarching goal: The amount of data stored, communicated, and processed is increasing exponentially, making data systems indispensable to our society. Data systems have grown to a humongous scale where non-ideal conditions such as failures and unavaiblabilities are the norm. Safety-critical applications are increasingly becoming data driven. The frontiers of computing are expanding into operating regimes which are inherently unreliable. Due to these trends, it is imperative to make data systems robust by design, while being resource efficient and performant. The overarching goal of our research is to design and build next-generation data systems that are robust, efficient and performant, spanning across the system stack including storage, computation, and communication.
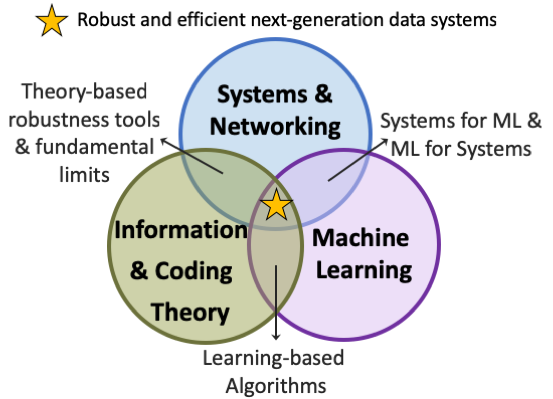
We take a multi-disciplinary approach, spanning computer systems and networking, information and coding theory, and machine learning. We design solutions that are rooted in fundamental theory and enhanced with machine learning, and build systems that employ the resulting solutions to advance the state-of-the-art in data systems. We also collaborate extensively with industry which enables us to (1) base our solutions on data from real-world production systems, and (2) make an impact on real-world practice. Our industry collaborators include Google, Microsoft, NetApp, Facebook, Cisco, Intel and Cloudera.
Here is our group's Github.
People:
I am fortunate to be advising and working with the following amazing students at CMU.
Current students:
PhD students:
Masters students:
Undergraduate students:
Graduated students:
PhD students:
Masters students:
Undergraduate students:
Support:
My group's research has been generously funded by NSF, Sloan Foundation, Open Compute Project (OCP), Google, Facebook/Meta, VMware, and Amazon Web Services. Support gratefully acknowledged.
People:
I am fortunate to be advising and working with the following amazing students at CMU.
Current students:
PhD students:
- Sanjith Athlur (co-advised with Greg Ganger)
- Timothy Kim (co-advised with Greg Ganger)
- Yixuan Mei
- Saransh Chopra
Masters students:
- Meredith Pan
- Frank Chen
Undergraduate students:
- Bob Chen
Graduated students:
PhD students:
- Juncheng (Jason) Yang (headed to Harvard University as a tenure track assistant professor)
- Francisco Maturana (CMU -> AWS Data Storage team)
- Michael Rudow (CMU -> McKinsey)
- Jack Kosaian (CMU -> Nvidia)
- Saurabh Kadekodi (co-advised with Greg Ganger) (CMU -> Research Scientist at Google)
Masters students:
- Justin Zhang (CMU -> Purdue Ph.D. student)
- Saransh Chopra (CMU -> CMU Ph.D. student)
- Timothy Kim (CMU -> CMU Ph.D. student)
- Jiyu Hu (CMU -> UIUC Ph.D. student)
- Kaige Liu (CMU -> Meta)
- Abhishek Kumar (CMU)
- Shaobo Guan (CMU)
- Arvind Sai Krishnan (CMU)
- Vilas Bhat (CMU -> Google)
- Jiaan Dai (CMU)
- Jiaqi Zuo (CMU)
- Jiongtao Ye (CMU)
- Xuren Zhou (CMU)
- Sai Kiriti Badam (CMU)
Undergraduate students:
- Justin Zhang (CMU -> CMU 5th year masters)
- Helen Wang (CMU)
- Tianyu Zhang (CMU -> CMU 5th year masters)
- Ziming Mao (Yale -> UC Berkeley Ph.D. student)
- Ian Chiu (CMU -> Instagram)
- Eliot Robson (CMU -> UIUC Ph. D. student)
- Chaitanya Mukka (BITS, India)
- Weizhong Zhang (Tsinghua University, China -> CMU Tepper PhD student)
- Sanya Agarwarl (CMU)
Support:
My group's research has been generously funded by NSF, Sloan Foundation, Open Compute Project (OCP), Google, Facebook/Meta, VMware, and Amazon Web Services. Support gratefully acknowledged.
Publications
(On Google Scholar)
Conference Papers
- "Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow"
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, K.V. Rashmi
ACM ASPLOS, 2025.
- "Morph: Efficient File-Lifetime Redundancy Management for Cluster File Systems"
Tim Kim, Sanjith Athlur, Saurabh Kadekodi, Francisco Maturana, Dax Delvira, Arif Merchant, Greg Ganger, K.V. Rashmi
ACM SOSP, 2024.
- "SIEVE: Simple and Efficient Eviction Policy for Turn-key Web Cache Replacement"
Yazhuo Zhang, Juncheng Yang, Yao Yue, Ymir Vigfusson, K.V. Rashmi
USENIX NSDI, 2024.Industry adoption, open source libraries, and media coverage: SIEVE website. - "On Low Field Size Constructions of Access-Optimal Convertible Codes" Saransh Chopra, Francisco Maturana, K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2024. - "Communication-efficient, Fault Tolerant PIR over Erasure Coded Storage"
Andrew Park, Trevor Leong, Francisco Maturana, Wenting Zheng, K. V. Rashmi
in IEEE Symposium on Security and Privacy (IEEE S&P), 2024. - "FIFO queues are all you need for cache eviction"
Juncheng Yang , Yazhuo Zhang, Ziyue Qiu, Yao Yue, K. V. Rashmi
ACM SOSP, 2023.Github Repo. See S3-FIFO repo.Industry adoption, open source libraries, and media coverage: S3-FIFO website. - "Efficient Fault Tolerance for Recommendation Model Training via Erasure Coding"
Tianyu Zhang, Kaige Liu, Jack Kosaian, Juncheng Yang, K. V. Rashmi
International Conference on Very Large Databases (VLDB), 2023. - "Locally Repairable Convertible Codes: Erasure Codes for Efficient Repair and Conversion"
Francisco Maturana, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2023. - "Learning-Augmented Streaming Codes for Variable-Size Messages Under Partial Burst Losses"
Michael Rudow, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2023. - "On expanding the toolkit of locality-based coded computation to the coordinates of inputs"
Michael Rudow, Venkatesan Guruswami, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2023. - "Compression-Informed Coded Computing"
Michael Rudow, Neophytos Charalambides, Alfred O. Hero III, and K.V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2023. - "Tambur: Efficient loss recovery for videoconferencing via streaming codes"
Michael Rudow, Francis Y. Yan, Abhishek Kumar, Ganesh Ananthanarayanan, Martin Ellis, and K.V. Rashmi
USENIX NSDI, 2023.Github Repo. See Tambur repo. - "GL-Cache: Group-level learning for efficient and high-performance caching"
Juncheng Yang, Ziming Mao, Yao Yue, K.V. Rashmi
USENIX FAST, 2023.Github Repo. See GL-Cache repo. - "Tiger: disk-adaptive redundancy without placement restrictions"
Saurabh Kadekodi*, Francisco Maturana*, Sanjith Athlur, Arif Merchant, K.V. Rashmi, Gregory R. Ganger
USENIX OSDI, 2022. - "C2DN: How to Harness Erasure Codes at the Edge for Efficient Content Delivery"
Juncheng Yang, Anirudh Sabnis, Daniel S. Berger, K. V. Rashmi, Ramesh K. Sitaraman
USENIX NSDI, 2022.Github Repo. See C2DN repo. - "Bandwidth Cost of Code Conversions in the Split Regime"
Francisco Maturana, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2022. - "Learning-Augmented Streaming Codes are Approximately Optimal for Variable-Size Messages"
Michael Rudow and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2022. - "Boosting the Throughput and Accelerator Utilization of Specialized CNNInference Beyond Increasing Batch Size"Jack Kosaian, Amar Phanishayee, Debadeepta Dey, Matthai Philipose, and K.V. Rashmi
International Conference on Machine Learning (ICML), 2021.
- "Arithmetic-Intensity-Guided Fault Tolerance for Neural Network Inference on GPUs"Jack Kosaian and K.V. Rashmi
ACM International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2021.
- "Segcache: memory-efficient and high-throughput in-memory cache for small objects"
Juncheng Yang, Yao Yue, K.V. Rashmi
USENIX NSDI, 2021.Github Repo. See Segcache repo. - "A locality-based lens for coded computation"
Michael Rudow, K.V. Rashmi, and Venkatesan Guruswami
IEEE International Symposium on Information Theory (ISIT), 2021.
- "Irregular Array Codes with Arbitrary Access Sets for Geo-Distributed Storage"
Francisco Maturana, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2021. - "Bandwidth Cost of Code Conversions in Distributed Storage: Fundamental Limits and Optimal Constructions"
Francisco Maturana, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2021. - A large scale of analysis of hundreds of in-memory cache
clusters at Twitter"
Juncheng Yang, Yao Yue, K.V. Rashmi
USENIX OSDI, 2020.Traces and analysis code open sourced. See TheSys Lab on Github for more information. - "Pacemaker: avoiding HeART attacks in storage clusters with
disk-adaptive redundancy"
Saurabh Kadekodi, Francisco Maturana, Suhas Jayaram Subramanya, Juncheng Yang, K.V. Rashmi, Gregory R. Ganger
USENIX OSDI, 2020. - "Access-optimal Linear MDS Convertible Codes for All Parameters"
Francisco Maturana, Chaitanya Mukka, and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2020. - "Online Versus Offline Rate in Streaming Codes for Variable-Size Messages"
Michael Rudow and K. V. Rashmi
IEEE International Symposium on Information Theory (ISIT), 2020. - "Convertible Codes: New Class of Codes for Efficient Conversion of Coded Data in Distributed Storage"Francisco Maturana and K. V. Rashmi
Innovations in Theoretical Computer Science (ITCS), 2020.
- "Parity Models: Erasure-Coded Resilience for Prediction Serving Systems"Jack Kosaian, K.V. Rashmi, and Shivaram Venkataraman
ACM SOSP, 2019.
(Slides) (Talk video) (Code available at TheSys Lab Github repo)
- "Vantage: Optimizing Video Upload for Time-shifted Viewing of Social Livestreams"Devdeep Ray, Jack Kosaian, K. V. Rashmi, and Srini Seshan
ACM SIGCOMM, 2019.
- "Cluster storage systems gotta have HeART: improving storage efficiency by exploiting disk-reliability heterogeneity"
Saurabh Kadekodi, K. V. Rashmi, and Greg Ganger
USENIX FAST, 2019. - "Streaming Codes for Variable-Size Arrivals"
Michael Rudow and K. V. Rashmi
Allerton Conference on Communication, Control, and Computing, 2018.
-
"EC-Cache: Load-Balanced, Low-Latency Cluster Caching with Online Erasure Coding"
K. V. Rashmi, Mosharaf Chowdhury, Jack Kosaian, Ion Stoica, and Kannan Ramchandran
USENIX OSDI, 2016. -
"Optimal Systematic Distributed Storage Codes with Fast Encoding"
Preetum Nakkiran, K. V. Rashmi and Kannan Ramchandran
IEEE International Symposium on Information Theory (ISIT), 2016. -
"Having Your Cake and Eating It Too: Jointly Optimal Erasure Codes for I/O, Storage, and Network-bandwidth"
K. V. Rashmi, Preetum Nakkiran, Jingyan Wang, Nihar B. Shah, and Kannan Ramchandran
USENIX FAST, Feb 2015.
Picked as the best paper of USENIX FAST 2015 by StorageMojo. -
"DART: Dropouts meet Multiple Additive Regression Trees"
K. V. Rashmi, and Ran Gilad-Bachrach
International Conference on Artificial Intelligence and Statistics (AISTATS), Feb 2015. - A "Hitchhiker's" Guide to Fast and Efficient Data Reconstruction in Erasure-coded Data Centers
K. V. Rashmi, Nihar B. Shah, Dikang Gu, Hairong Kuang, Dhruba Borthakur, and Kannan Ramchandran
ACM SIGCOMM, Aug 2014.Press: The Morning PaperPress: StorageMojo - "One Extra Bit of Download Ensures Perfectly Private Information Retrieval"
Nihar B. Shah, K. V. Rashmi and Kannan Ramchandran
IEEE International Symposium on Information Theory (ISIT), 2014. - "Fundamental Limits on Communication for Oblivious Updates in Storage Networks"
Preetum Nakkiran, Nihar B. Shah, and K. V. Rashmi
IEEE GLOBECOM, 2014. - "A Piggybacking Design Framework for Read-and Download-efficient Distributed Storage Codes"
K. V. Rashmi*, Nihar B. Shah* and Kannan Ramchandran
IEEE International Symposium on Information Theory (ISIT), July 2013. - "Secure network coding for distributed secret sharing with low communication cost"
Nihar B. Shah, K. V. Rashmi, and Kannan Ramchandran
IEEE International Symposium on Information Theory (ISIT), July 2013. - "Regenerating Codes for Errors and Erasures in Distributed Storage"
K. V. Rashmi*, Nihar B. Shah*, Kannan Ramchandran, and P. Vijay Kumar
IEEE International Symposium on Information Theory (ISIT), July 2012. - "Information-theoretically Secure Regenerating Codes for Distributed Storage"
Nihar B. Shah*, K. V. Rashmi* and P. Vijay Kumar
IEEE Globecom, Houston, Dec. 2011. - "Enabling Node Repair in Any Erasure Code for Distributed Storage"
K. V. Rashmi*, Nihar B. Shah* and P. Vijay Kumar
IEEE International Symposium on Information Theory (ISIT), St. Petersburg, 2011. - "A Flexible Class of Regenerating Codes for Distributed Storage"
Nihar B. Shah*, K. V. Rashmi* and P. Vijay Kumar
IEEE International Symposium on Information Theory (ISIT), Austin, June 2010. - "Explicit and Optimal Exact-Regenerating Codes for the Minimum-Bandwidth Point in Distributed Storage"
K. V. Rashmi*, Nihar B. Shah*, P. Vijay Kumar and Kannan Ramchandran
IEEE International Symposium on Information Theory (ISIT), Austin, June 2010. - "Explicit Codes Minimizing Repair Bandwidth for Distributed Storage"
Nihar B. Shah*, K. V. Rashmi*, P. Vijay Kumar and Kannan Ramchandran
IEEE Information Theory Workshop (ITW), Cairo, Jan.2010. - "Explicit Construction of Optimal Exact Regenerating Codes for Distributed Storage"
K. V. Rashmi*, Nihar B. Shah*, P. Vijay Kumar and Kannan Ramchandran
Allerton Conf., Urbana-Champaign, Sep.2009.
Workshop Papers
- "Rethinking Erasure-Coding Libraries in the Age of Optimized Machine Learning"
Jiyu Hu, Jack Kosaian, K. V. Rashmi,
USENIX HotStorage, 2024. - "FIFO Can be Better than LRU: the Power of Lazy Promotion and Quick Demotion"
Juncheng Yang , Ziyue Qiu, Yazhuo Zhang, Yao Yue, K. V. Rashmi
Workshop on Hot Topics in Operating Systems (HotOS), 2023. - "Erasure-Coding-Based Fault Tolerance for Recommendation Model Training"
Kaige Liu, Jack Kosaian, K.V. Rashmi Vinayak
International Symposium on Checkpointing for Supercomputing (SuperCheck), workshop held in conjuction with ACM SuperComputing (SC) 2021. - "A Solution to the Network Challenges of Data Recovery in Erasure-coded Distributed Storage Systems: A Study on the Facebook Warehouse Cluster"
K. V. Rashmi, Nihar B. Shah, Dikang Gu, Hairong Kuang, Dhruba Borthakur, and Kannan Ramchandran
USENIX HotStorage, June 2013.
Journal Papers
- "Bandwidth Cost of Code Conversions in Distributed Storage: Fundamental Limits and Optimal Constructions"
Francisco Maturana and K. V. Rashmi
IEEE Transactions on Information Theory, 2023. - "Online Versus Offline Rate in Streaming Codes for Variable-Size Messages"
Michael Rudow and K. V. Rashmi
IEEE Transactions on Information Theory, 2023. - "Convertible Codes: Enabling Efficient Conversion of Coded Data in Distributed Storage"
Francisco Maturana and K. V. Rashmi
IEEE Transactions on Information Theory, 2022. - "Streaming Codes for Variable-Size Messages"
Michael Rudow and K. V. Rashmi
IEEE Transactions on Information Theory, 2022. - "A large scale of analysis of hundreds of in-memory cache clusters at Twitter"
Juncheng Yang, Yao Yue and K.V. Rashmi
ACM Transactions on Storage, August 2021.
Code repository available on Github. - "Learning-Based Coded-Computation"
Jack Kosaian, K.V. Rashmi, and Shivaram Venkataraman,
IEEE Journal on Selected Areas in Information Theory, March 2020.
Code repository available on Github. - "Information-theoretically Secure Erasure Codes for Distributed Storage"
K. V. Rashmi*, Nihar B. Shah*, Kannan Ramchandran, and P. Vijay Kumar
IEEE Transactions on Information Theory, Mar. 2018. - "A Piggybacking Design Framework for Read-and Download-efficient Distributed Storage Codes"
K. V. Rashmi, Nihar B. Shah and Kannan Ramchandran
IEEE Transactions on Information Theory, Sept. 2017. - "Distributed Secret Dissemination Across a Network"
Nihar B. Shah, K. V. Rashmi, and Kannan Ramchandran
IEEE Journal of Selected Topics in Signal Processing, October 2015.
- "Optimal Exact-Regenerating Codes for Distributed Storage at the MSR and MBR Points via a Product-Matrix Construction"
K. V. Rashmi*, Nihar B. Shah* and P. Vijay Kumar
IEEE Transactions on Information Theory, August 2011.
- "Distributed Storage Codes with Repair-by-Transfer and Non-achievability of Interior Points on the Storage-Bandwidth Tradeoff"
Nihar B. Shah*, K. V. Rashmi*, P. Vijay Kumar and Kannan Ramchandran
IEEE Transactions on Information Theory, March 2012.
- "Interference Alignment in Regenerating Codes for Distributed Storage: Necessity and Code Constructions"
Nihar B. Shah*, K. V. Rashmi*, P. Vijay Kumar and Kannan Ramchandran
IEEE Transactions on Information Theory, April 2012.
Teaching
Fall 2024: 15-750 Algorithms in the real worldSpring 2024: 15-440/640 Distributed Systems
Fall 2023: 15-750 Algorithms in the real world
Spring 2022: 15-750 Algorithms in the real world
Fall 2021: 15-440/640 Distributed Systems
Spring 2021: 15-750 Graduate Algorithms
Fall 2020: 15-440/640 Distributed Systems
Spring 2020: 15-440/640 Distributed Systems
Fall 2019: 15-853 Algorithms in the real world
Fall 2018: 15-848 Practical information and coding theory for computer systems
Spring 2018: 15-359/659 Probability and computing