Imitation Learning
In sequential decision-making problems, Imitation learning (IL) posits to learn from the behavior of an expert given a collection of demonstrations, in the absence of reward feedback. In the past, several works have studied the performance of supervised learning approaches such as behavior cloning (Ross and Bagnell 2010), interactive approaches such as DAgger (Ross and Bagnell 2011) among others. However, from a theoretical point of view, the statistical rates in even the simplest setting of episodic and tabular MDPs was not well understood. In this line of work, we establish tight bounds for IL in the tabular setting, and establish that error compounding is avoidable in imitation learning if the MDP transition is known. These algorithmic ideas can be extended beyond, to the case of function approximation, where sub-quadratic bounds in the horizon are achievable if it is possible to carry out “parameter estimation” in a statistically efficient manner. We also present preliminary results on the case of Imitation Learning with an optimal expert, and show that the picture is far more complicated here, even in the simplest tabular setting.

Publications
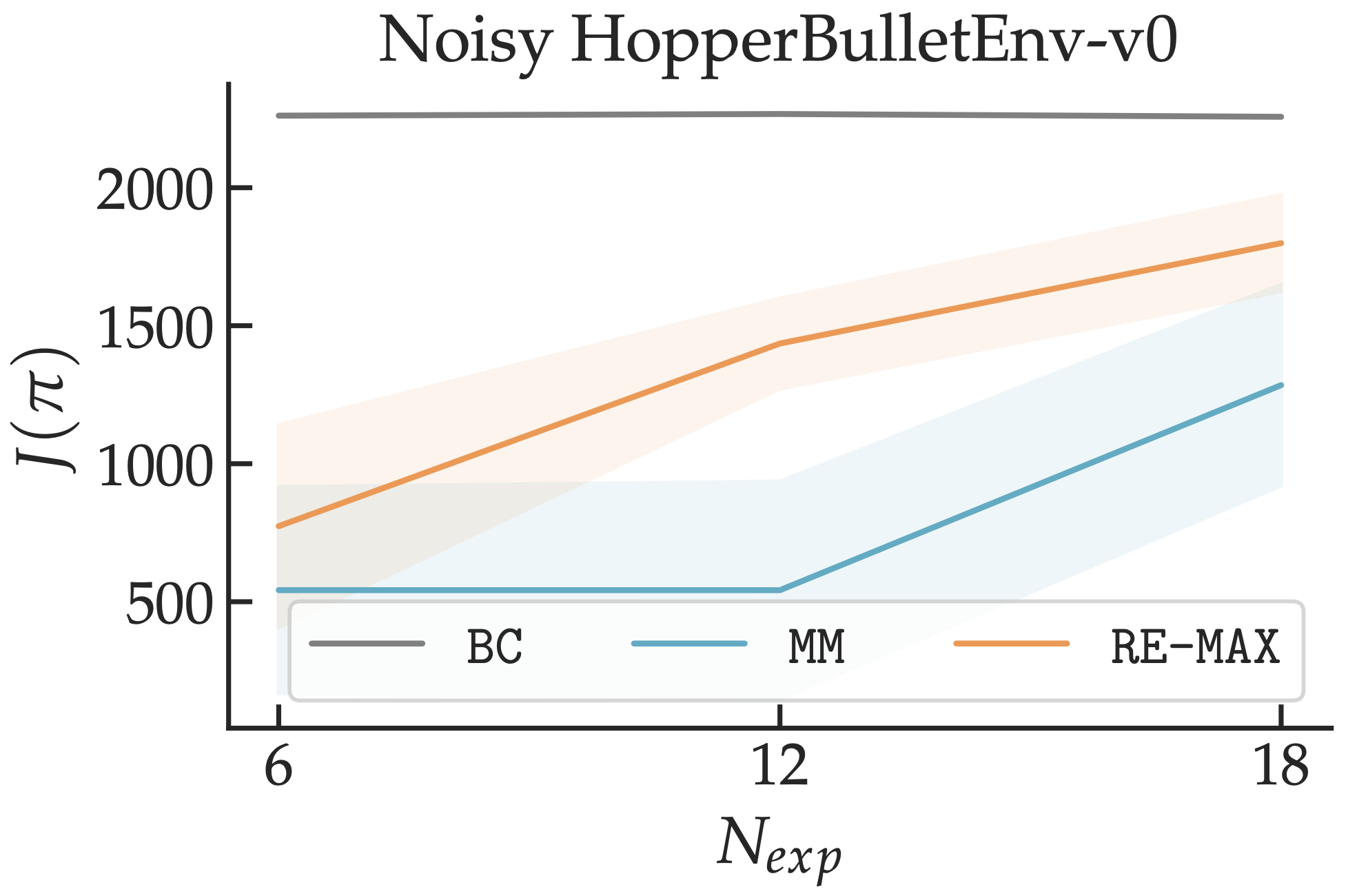
G. Swamy, N. Rajaraman, M. Peng, S. Choudhury, D. Bagnell, S. Wu, J. Jiao, K. Ramchandran, “Minimax Optimal Online Imitation Learning via Replay Estimation”, OpenReview 2022.
N. Rajaraman, Y. Han, L.F. Yang, J. Jiao, K. Ramchandran, “Provably Breaking the Quadratic Error Compounding Barrier in Imitation Learning, Optimally”, arXiv 2021.
N. Rajaraman, Y. Han, L.F. Yang, J. Liu, J. Jiao, K. Ramchandran, “On the Value of Interaction and Function Approximation in Imitation Learning”, NeurIPS 2021.
N. Rajaraman, L.F. Yang, J. Jiao, K. Ramchandran, “Toward the Fundamental Limits of Imitation Learning”, NeurIPS 2020.